Les bases de Git
- Démarrer un dépôt Git
- Enregistrer des modifications dans le dépôt
- Visualiser l’historique des validations
- Annuler des actions
- Travailler avec des dépôts distants
- Étiquetage
- Les alias Git
- Résumé
Si vous ne deviez lire qu’un chapitre avant de commencer à utiliser Git, c’est celui-ci. Ce chapitre couvre les commandes de base nécessaires pour réaliser la vaste majorité des activités avec Git. À la fin de ce chapitre, vous devriez être capable de configurer et initialiser un dépôt, commencer et arrêter le suivi de version de fichiers, d’indexer et valider des modifications. Nous vous montrerons aussi comment paramétrer Git pour qu’il ignore certains fichiers ou patrons de fichiers, comment revenir sur les erreurs rapidement et facilement, comment parcourir l’historique de votre projet et voir les modifications entre deux validations, et comment pousser et tirer les modifications avec des dépôts distants.
Démarrer un dépôt Git
Vous pouvez principalement démarrer un dépôt Git de deux manières. La première consiste à prendre un projet ou un répertoire existant et à l’importer dans Git. La seconde consiste à cloner un dépôt Git existant sur un autre serveur.
Initialisation d’un dépôt Git dans un répertoire existant
Si vous commencez à suivre un projet existant dans Git, vous n’avez qu’à vous positionner dans le répertoire du projet et saisir :
$ git init
Cela crée un nouveau sous-répertoire nommé .git qui contient tous les
fichiers nécessaires au dépôt — un squelette de dépôt Git. Pour
l’instant, aucun fichier n’est encore versionné. (Cf. Les tripes de
Git pour plus d’information sur les fichiers
contenus dans le répertoire .git que vous venez de créer.)
Si vous souhaitez démarrer le contrôle de version sur des fichiers
existants (par opposition à un répertoire vide), vous devrez
probablement suivre ces fichiers et faire un commit initial. Vous pouvez
le réaliser avec quelques commandes add qui spécifient les fichiers
que vous souhaitez suivre, suivies par un git commit :
$ git add *.c
$ git add LICENSE
$ git commit -m 'initial project version'
Cloner un dépôt existant
Si vous souhaitez obtenir une copie d’un dépôt Git existant — par
exemple, un projet auquel vous aimeriez contribuer — la commande dont
vous avez besoin s’appelle git clone. Si vous êtes familier avec
d’autres systèmes de gestion de version tels que Subversion, vous
noterez que la commande est clone et non checkout. C’est une
distinction importante — Git reçoit une copie de quasiment toutes les
données dont le serveur dispose. Toutes les versions de tous les
fichiers pour l’historique du projet sont téléchargées quand vous lancez
git clone. En fait, si le disque du serveur se corrompt, vous pouvez
utiliser n’importe quel clone pour remettre le serveur dans l’état où il
était au moment du clonage (vous pourriez perdre quelques paramètres du
serveur, mais toutes les données sous gestion de version seraient
récupérées — cf. Installation de Git sur un
serveur pour de plus amples détails).
Vous clonez un dépôt avec git clone [url]. Par exemple, si vous voulez
cloner la bibliothèque logicielle Git appelée libgit2, vous pouvez le
faire de la manière suivante :
$ git clone https://github.com/libgit2/libgit2
Ceci crée un répertoire nommé “libgit2”, initialise un répertoire .git
à l’intérieur, récupère toutes les données de ce dépôt, et extrait une
copie de travail de la dernière version. Si vous examinez le nouveau
répertoire libgit2, vous y verrez les fichiers du projet, prêts à être
modifiés ou utilisés. Si vous souhaitez cloner le dépôt dans un
répertoire nommé différemment, vous pouvez spécifier le nom dans une
option supplémentaire de la ligne de commande :
$ git clone https://github.com/libgit2/libgit2 monlibgit2
Cette commande réalise la même chose que la précédente, mais le
répertoire cible s’appelle monlibgit2.
Git dispose de différents protocoles de transfert que vous pouvez
utiliser. L’exemple précédent utilise le protocole https://, mais vous
pouvez aussi voir git:// ou utilisateur@serveur:/chemin.git, qui
utilise le protocole de transfert SSH. Installation de Git sur un
serveur introduit toutes les options disponibles
pour mettre en place un serveur Git, ainsi que leurs avantages et
inconvénients.
Enregistrer des modifications dans le dépôt
Vous avez à présent un dépôt Git valide et une extraction ou copie de travail du projet. Vous devez faire quelques modifications et valider des instantanés de ces modifications dans votre dépôt chaque fois que votre projet atteint un état que vous souhaitez enregistrer.
Souvenez-vous que chaque fichier de votre copie de travail peut avoir deux états : sous suivi de version ou non suivi. Les fichiers suivis sont les fichiers qui appartenaient déjà au dernier instantané ; ils peuvent être inchangés, modifiés ou indexés. Tous les autres fichiers sont non suivis — tout fichier de votre copie de travail qui n’appartenait pas à votre dernier instantané et n’a pas été indexé. Quand vous clonez un dépôt pour la première fois, tous les fichiers seront sous suivi de version et inchangés car Git vient tout juste de les extraire et vous ne les avez pas encore édités.
Au fur et à mesure que vous éditez des fichiers, Git les considère comme modifiés, car vous les avez modifiés depuis le dernier instantané. Vous indexez ces fichiers modifiés et vous enregistrez toutes les modifications indexées, puis ce cycle se répète.
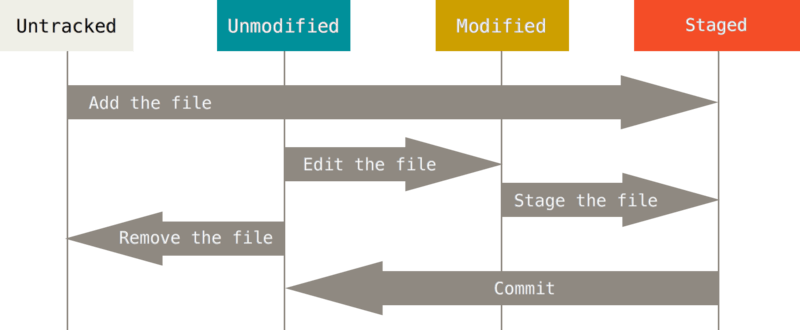
Figure 8. Le cycle de vie des états des fichiers.
Vérifier l’état des fichiers
L’outil principal pour déterminer quels fichiers sont dans quel état est
la commande git status. Si vous lancez cette commande juste après un
clonage, vous devriez voir ce qui suit :
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
rien à valider, la copie de travail est propre
Ce message signifie que votre copie de travail est propre, en d’autres termes, aucun fichier suivi n’a été modifié. Git ne voit pas non plus de fichiers non-suivis, sinon ils seraient listés ici. Enfin, la commande vous indique sur quelle branche vous êtes. Pour l’instant, c’est toujours “master”, qui correspond à la valeur par défaut ; nous ne nous en soucierons pas maintenant. Dans Les branches avec Git, nous parlerons plus en détail des branches et des références.
Supposons que vous souhaitez ajouter un nouveau fichier au projet, un
simple fichier LISEZMOI. Si le fichier n’existait pas auparavant, et si
vous lancez git status, vous voyez votre fichier non suivi comme
suit :
$ echo 'Mon Projet' > LISEZMOI
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Fichiers non suivis:
(utilisez "git add <fichier>..." pour inclure dans ce qui sera validé)
LISEZMOI
aucune modification ajoutée à la validation mais des fichiers non suivis sont présents (utilisez "git add" pour les suivre)
Vous pouvez constater que votre nouveau fichier LISEZMOI n’est pas en
suivi de version, car il apparaît dans la section « Fichiers non
suivis » de l’état de la copie de travail. « non suivi » signifie
simplement que Git détecte un fichier qui n’était pas présent dans le
dernier instantané ; Git ne le placera sous suivi de version que quand
vous lui indiquerez de le faire. Ce comportement permet de ne pas placer
accidentellement sous suivi de version des fichiers binaires générés ou
d’autres fichiers que vous ne voulez pas inclure. Mais vous voulez
inclure le fichier LISEZMOI dans l’instantané, alors commençons à
suivre ce fichier.
Placer de nouveaux fichiers sous suivi de version
Pour commencer à suivre un nouveau fichier, vous utilisez la commande
git add. Pour commencer à suivre le fichier LISEZMOI, vous pouvez
entrer ceci :
$ git add LISEZMOI
Si vous lancez à nouveau la commande git status, vous pouvez constater
que votre fichier LISEZMOI est maintenant suivi et indexé :
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
nouveau fichier : LISEZMOI
Vous pouvez affirmer qu’il est indexé car il apparaît dans la section
« Modifications qui seront validées ». Si vous validez à ce moment, la
version du fichier à l’instant où vous lancez git add est celle qui
sera dans l’historique des instantanés. Vous pouvez vous souvenir que
lorsque vous avez précédemment lancé git init, vous avez ensuite lancé
git add (fichiers) — c’était bien sûr pour commencer à placer sous
suivi de version les fichiers de votre répertoire de travail. La
commande git add accepte en paramètre un chemin qui correspond à un
fichier ou un répertoire ; dans le cas d’un répertoire, la commande
ajoute récursivement tous les fichiers de ce répertoire.
Indexer des fichiers modifiés
Maintenant, modifions un fichier qui est déjà sous suivi de version. Si
vous modifiez le fichier sous suivi de version appelé CONTRIBUTING.md
et que vous lancez à nouveau votre commande git status, vous verrez
ceci :
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
nouveau fichier : LISEZMOI
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : CONTRIBUTING.md
Le fichier CONTRIBUTING.md apparaît sous la section nommée
« Modifications qui ne seront pas validées » ce qui signifie que le
fichier sous suivi de version a été modifié dans la copie de travail
mais n’est pas encore indexé. Pour l’indexer, il faut lancer la commande
git add. git add est une commande multi-usage — elle peut être
utilisée pour placer un fichier sous suivi de version, pour indexer un
fichier ou pour d’autres actions telles que marquer comme résolus des
conflits de fusion de fichiers. Sa signification s’approche plus de
« ajouter ce contenu pour la prochaine validation » que de « ajouter ce
contenu au projet ». Lançons maintenant git add pour indexer le
fichier CONTRIBUTING.md, et relançons la commande git status :
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
nouveau fichier : LISEZMOI
modifié : CONTRIBUTING.md
À présent, les deux fichiers sont indexés et feront partie de la
prochaine validation. Mais supposons que vous souhaitiez apporter encore
une petite modification au fichier CONTRIBUTING.md avant de réellement
valider la nouvelle version. Vous l’ouvrez à nouveau, réalisez la petite
modification et vous voilà prêt à valider. Néanmoins, vous lancez
git status une dernière fois :
$ vim CONTRIBUTING.md
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
nouveau fichier : LISEZMOI
modifié : CONTRIBUTING.md
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : CONTRIBUTING.md
Que s’est-il donc passé ? À présent, CONTRIBUTING.md apparaît à la
fois comme indexé et non indexé. En fait, Git indexe un fichier dans son
état au moment où la commande git add est lancée. Si on valide les
modifications maintenant, la version de CONTRIBUTING.md qui fera
partie de l’instantané est celle correspondant au moment où la commande
git add CONTRIBUTING.md a été lancée, et non la version actuellement
présente dans la copie de travail au moment où la commande git commit
est lancée. Si le fichier est modifié après un git add, il faut
relancer git add pour prendre en compte l’état actuel de la copie de
travail :
$ git add CONTRIBUTING.md
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
nouveau fichier : LISEZMOI
modifié : CONTRIBUTING.md
Statut court
Bien que git status soit informatif, il est aussi plutôt verbeux. Git
a aussi une option de status court qui permet de voir les modifications
de façon plus compacte. Si vous lancez git status -s ou
git status --short, vous obtenez une information bien plus simple.
$ git status -s
M README
MM Rakefile
A lib/git.rb
M lib/simplegit.rb
?? LICENSE.txt
Les nouveaux fichiers qui ne sont pas suivis sont précédés de ??, les
fichiers nouveaux et indexés sont précédés de A, les fichiers modifiés
de M et ainsi de suite. Il y a deux colonnes d’état - celle de gauche
indique l’état de l’index et celle de droite l’état du dossier de
travail. Donc l’exemple ci-dessus indique que le fichier README est
modifié dans le répertoire de travail mais n’est pas encore indexé,
tandis que le fichier lib/simplegit.rb est modifié et indexé. Le
fichier Rakefile a été modifié, indexé puis modifié à nouveau, de
sorte qu’il a des modifications à la fois indexées et non-indexées.
Ignorer des fichiers
Il apparaît souvent qu’un type de fichiers présent dans la copie de
travail ne doit pas être ajouté automatiquement ou même ne doit pas
apparaître comme fichier potentiel pour le suivi de version. Ce sont par
exemple des fichiers générés automatiquement tels que les fichiers de
journaux ou de sauvegardes produits par l’outil que vous utilisez. Dans
un tel cas, on peut énumérer les patrons de noms de fichiers à ignorer
dans un fichier .gitignore. Voici ci-dessous un exemple de fichier
.gitignore :
$ cat .gitignore
*.[oa]
*~
La première ligne ordonne à Git d’ignorer tout fichier se terminant en
.o ou .a — des fichiers objet ou archive qui sont généralement
produits par la compilation d’un programme. La seconde ligne indique à
Git d’ignorer tous les fichiers se terminant par un tilde (~), ce qui
est le cas des noms des fichiers temporaires pour de nombreux éditeurs
de texte tels qu’Emacs. On peut aussi inclure un répertoire log, tmp
ou pid, ou le répertoire de documentation générée automatiquement, ou
tout autre fichier. Renseigner un fichier .gitignore avant de
commencer à travailler est généralement une bonne idée qui évitera de
valider par inadvertance des fichiers qui ne doivent pas apparaître dans
le dépôt Git.
Les règles de construction des patrons à placer dans le fichier
.gitignore sont les suivantes :
les lignes vides ou commençant par
#sont ignorées ;les patrons standards de fichiers sont utilisables ;
si le patron se termine par une barre oblique (
/), il indique un répertoire ;un patron commençant par un point d’exclamation (
!) indique des fichiers à inclure malgré les autres règles.
Les patrons standards de fichiers sont des expressions régulières
simplifiées utilisées par les shells. Un astérisque (*) correspond à
un ou plusieurs caractères ; [abc] correspond à un des trois
caractères listés dans les crochets, donc a ou b ou c ; un point
d’interrogation (?) correspond à un unique caractère ; des crochets
entourant des caractères séparés par un tiret ([0-9]) correspond à un
caractère dans l’intervalle des deux caractères indiqués, donc ici de 0
à 9. Vous pouvez aussi utiliser deux astérisques pour indiquer une série
de répertoires inclus ; a/**/z correspond donc à a/z, a/b/z,
a/b/c/z et ainsi de suite.
Voici un autre exemple de fichier .gitignore :
# pas de fichier .a
*.a
# mais suivre lib.a malgré la règle précédente
!lib.a
# ignorer uniquement le fichier TODO à la racine du projet
/TODO
# ignorer tous les fichiers dans le répertoire build
build/
# ignorer doc/notes.txt, mais pas doc/server/arch.txt
doc/*.txt
# ignorer tous les fichiers .txt sous le répertoire doc/
doc/**/*.txt
GitHub maintient une liste assez complète d’exemples de fichiers |
Inspecter les modifications indexées et non indexées
Si le résultat de la commande git status est encore trop vague —
lorsqu’on désire savoir non seulement quels fichiers ont changé mais
aussi ce qui a changé dans ces fichiers — on peut utiliser la commande
git diff. Cette commande sera traitée en détail plus loin ; mais elle
sera vraisemblablement utilisée le plus souvent pour répondre aux
questions suivantes : qu’est-ce qui a été modifié mais pas encore
indexé ? Quelle modification a été indexée et est prête pour la
validation ? Là où git status répond de manière générale à ces
questions, git diff montre les lignes exactes qui ont été ajoutées,
modifiées ou effacées — le patch en somme.
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
nouveau fichier : LISEZMOI
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : CONTRIBUTING.md
Pour visualiser ce qui a été modifié mais pas encore indexé, tapez
git diff sans autre argument :
$ git diff
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8ebb991..643e24f 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -65,7 +65,8 @@ branch directly, things can get messy.
Please include a nice description of your changes when you submit your PR;
if we have to read the whole diff to figure out why you're contributing
in the first place, you're less likely to get feedback and have your change
-merged in.
+merged in. Also, split your changes into comprehensive chunks if you patch is
+longer than a dozen lines.
If you are starting to work on a particular area, feel free to submit a PR
that highlights your work in progress (and note in the PR title that it's
Cette commande compare le contenu du répertoire de travail avec la zone d’index. Le résultat vous indique les modifications réalisées mais non indexées.
Si vous souhaitez visualiser les modifications indexées qui feront
partie de la prochaine validation, vous pouvez utiliser
git diff --cached (avec les versions 1.6.1 et supérieures de Git, vous
pouvez aussi utiliser git diff --staged, qui est plus mnémotechnique).
Cette commande compare les fichiers indexés et le dernier instantané :
$ git diff --staged
diff --git a/LISEZMOI b/LISEZMOI
new file mode 100644
index 0000000..1e17b0c
--- /dev/null
+++ b/LISEZMOI
@@ -0,0 +1 @@
+Mon Projet
Il est important de noter que git diff ne montre pas les modifications
réalisées depuis la dernière validation — seulement les modifications
qui sont non indexées. Cela peut introduire une confusion car si tous
les fichiers modifiés ont été indexés, git diff n’indiquera aucun
changement.
Par exemple, si vous indexez le fichier CONTRIBUTING.md et l’éditez
ensuite, vous pouvez utiliser git diff pour visualiser les
modifications indexées et non indexées de ce fichier. Si l’état est le
suivant :
$ git add CONTRIBUTING.md
$ echo 'ligne de test' >> CONTRIBUTING.md
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
nouveau fichier : CONTRIBUTING.md
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : CONTRIBUTING.md
À présent, vous pouvez utiliser git diff pour visualiser les
modifications non indexées :
$ git diff
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 643e24f..87f08c8 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -119,3 +119,4 @@ at the
## Starter Projects
See our [projects list](https://github.com/libgit2/libgit2/blob/development/PROJECTS.md).
+ligne de test
et git diff --cached pour visualiser ce qui a été indexé jusqu’à
maintenant :
$ git diff --cached
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8ebb991..643e24f 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -65,7 +65,8 @@ branch directly, things can get messy.
Please include a nice description of your changes when you submit your PR;
if we have to read the whole diff to figure out why you're contributing
in the first place, you're less likely to get feedback and have your change
-merged in.
+merged in. Also, split your changes into comprehensive chunks if you patch is
+longer than a dozen lines.
If you are starting to work on a particular area, feel free to submit a PR
that highlights your work in progress (and note in the PR title that it's
Git Diff dans un outil externe
Nous allons continuer à utiliser la commande |
Valider vos modifications
Maintenant que votre zone d’index est dans l’état désiré, vous pouvez
valider vos modifications. Souvenez-vous que tout ce qui est encore non
indexé — tous les fichiers qui ont été créés ou modifiés mais n’ont pas
subi de git add depuis que vous les avez modifiés — ne feront pas
partie de la prochaine validation. Ils resteront en tant que fichiers
modifiés sur votre disque.
Dans notre cas, la dernière fois que vous avez lancé git status, vous
avez vérifié que tout était indexé, et vous êtes donc prêt à valider vos
modifications. La manière la plus simple de valider est de taper
git commit :
$ git commit
Cette action lance votre éditeur par défaut (qui est paramétré par la
variable d’environnement $EDITOR de votre shell — habituellement vim
ou Emacs, mais vous pouvez le paramétrer spécifiquement pour Git en
utilisant la commande git config --global core.editor comme nous
l’avons vu au Démarrage rapide).
L’éditeur affiche le texte suivant :
# Veuillez saisir le message de validation pour vos modifications. Les lignes
# commençant par '#' seront ignorées, et un message vide abandonne la validation.
# Sur la branche master
# Votre branche est à jour avec 'origin/master'.
#
# Modifications qui seront validées :
# nouveau fichier : LISEZMOI
# modifié : CONTRIBUTING.md
#
Vous constatez que le message de validation par défaut contient une
ligne vide suivie en commentaire par le résultat de la commande
git status. Vous pouvez effacer ces lignes de commentaire et saisir
votre propre message de validation, ou vous pouvez les laisser en place
pour vous aider à vous rappeler ce que vous êtes en train de valider
(pour un rappel plus explicite de ce que vous avez modifié, vous pouvez
aussi passer l’option -v à la commande git commit). Cette option
place le résultat du diff en commentaire dans l’éditeur pour vous
permettre de visualiser exactement ce que vous avez modifié. Quand vous
quittez l’éditeur (après avoir sauvegardé le message), Git crée votre
commit avec ce message de validation (après avoir retiré les
commentaires et le diff).
Autrement, vous pouvez spécifier votre message de validation en ligne
avec la commande git commit en le saisissant après l’option -m,
comme ceci :
$ git commit -m "Story 182: Fix benchmarks for speed"
[master 463dc4f] Story 182: Fix benchmarks for speed
2 files changed, 2 insertions(+)
create mode 100644 LISEZMOI
À présent, vous avez créé votre premier commit ! Vous pouvez constater
que le commit vous fournit quelques informations sur lui-même : sur
quelle branche vous avez validé (master), quelle est sa somme de
contrôle SHA-1 (463dc4f), combien de fichiers ont été modifiés, et
quelques statistiques sur les lignes ajoutées et effacées dans ce
commit.
Souvenez-vous que la validation enregistre l’instantané que vous avez préparé dans la zone d’index. Tout ce que vous n’avez pas indexé est toujours en état modifié ; vous pouvez réaliser une nouvelle validation pour l’ajouter à l’historique. À chaque validation, vous enregistrez un instantané du projet en forme de jalon auquel vous pourrez revenir ou avec lequel comparer votre travail ultérieur.
Passer l’étape de mise en index
Bien qu’il soit incroyablement utile de pouvoir organiser les commits
exactement comme on l’entend, la gestion de la zone d’index est parfois
plus complexe que nécessaire dans le cadre d’une utilisation normale. Si
vous souhaitez éviter la phase de placement des fichiers dans la zone
d’index, Git fournit un raccourci très simple. L’ajout de l’option -a
à la commande git commit ordonne à Git de placer automatiquement tout
fichier déjà en suivi de version dans la zone d’index avant de réaliser
la validation, évitant ainsi d’avoir à taper les commandes git add :
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : CONTRIBUTING.md
aucune modification n'a été ajoutée à la validation (utilisez "git add" ou "git commit -a")
$ git commit -a -m 'added new benchmarks'
[master 83e38c7] added new benchmarks
1 file changed, 5 insertions(+), 0 deletions(-)
Notez bien que vous n’avez pas eu à lancer git add sur le fichier
CONTRIBUTING.md avant de valider.
Effacer des fichiers
Pour effacer un fichier de Git, vous devez l’éliminer des fichiers en
suivi de version (plus précisément, l’effacer dans la zone d’index) puis
valider. La commande git rm réalise cette action mais efface aussi ce
fichier de votre copie de travail de telle sorte que vous ne le verrez
pas réapparaître comme fichier non suivi en version à la prochaine
validation.
Si vous effacez simplement le fichier dans votre copie de travail, il
apparaît sous la section « Modifications qui ne seront pas validées »
(c’est-à-dire, non indexé) dans le résultat de git status :
$ rm PROJECTS.md
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui ne seront pas validées :
(utilisez "git add/rm <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
supprimé : PROJECTS.md
aucune modification n'a été ajoutée à la validation (utilisez "git add" ou "git commit -a")
Ensuite, si vous lancez git rm, l’effacement du fichier est indexé :
$ git rm PROJECTS.md
rm 'PROJECTS.md'
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
supprimé : PROJECTS.md
Lors de la prochaine validation, le fichier sera absent et non-suivi en
version. Si vous avez auparavant modifié et indexé le fichier, son
élimination doit être forcée avec l’option -f. C’est une mesure de
sécurité pour empêcher un effacement accidentel de données qui n’ont pas
encore été enregistrées dans un instantané et qui seraient
définitivement perdues.
Un autre scénario serait de vouloir abandonner le suivi de version d’un
fichier tout en le conservant dans la copie de travail. Ceci est
particulièrement utile lorsqu’on a oublié de spécifier un patron dans le
fichier .gitignore et on a accidentellement indexé un fichier, tel
qu’un gros fichier de journal ou une série d’archives de compilation
.a. Pour réaliser ce scénario, utilisez l’option --cached :
$ git rm --cached LISEZMOI
Vous pouvez spécifier des noms de fichiers ou de répertoires, ou des
patrons de fichiers à la commande git rm. Cela signifie que vous
pouvez lancer des commandes telles que :
$ git rm log/\*.log
Notez bien la barre oblique inverse (\) devant *. Il est nécessaire
d’échapper le caractère * car Git utilise sa propre expansion de nom
de fichier en addition de l’expansion du shell. Ce caractère
d’échappement doit être omis sous Windows si vous utilisez le terminal
système. Cette commande efface tous les fichiers avec l’extension .log
présents dans le répertoire log/. Vous pouvez aussi lancer une
commande telle que :
$ git rm \*~
Cette commande élimine tous les fichiers se terminant par ~.
Déplacer des fichiers
À la différence des autres VCS, Git ne suit pas explicitement les mouvements des fichiers. Si vous renommez un fichier suivi par Git, aucune méta-donnée indiquant le renommage n’est stockée par Git. Néanmoins, Git est assez malin pour s’en apercevoir après coup — la détection de mouvement de fichier sera traitée plus loin.
De ce fait, que Git ait une commande mv peut paraître trompeur. Si
vous souhaitez renommer un fichier dans Git, vous pouvez lancer quelque
chose comme :
$ git mv nom_origine nom_cible
et cela fonctionne. En fait, si vous lancez quelque chose comme ceci et
inspectez le résultat d’une commande git status, vous constaterez que
Git gère le renommage de fichier :
$ git mv LISEZMOI.txt LISEZMOI
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
renommé : LISEZMOI.txt -> LISEZMOI
Néanmoins, cela revient à lancer les commandes suivantes :
$ mv LISEZMOI.txt LISEZMOI
$ git rm LISEZMOI.txt
$ git add LISEZMOI
Git trouve implicitement que c’est un renommage, donc cela importe peu
si vous renommez un fichier de cette manière ou avec la commande mv.
La seule différence réelle est que git mv ne fait qu’une commande à
taper au lieu de trois — c’est une commande de convenance. Le point
principal est que vous pouvez utiliser n’importe quel outil pour
renommer un fichier, et traiter les commandes add/rm plus tard,
avant de valider la modification.
Visualiser l’historique des validations
Après avoir créé plusieurs commits ou si vous avez cloné un dépôt
ayant un historique de commits, vous souhaitez probablement revoir le
fil des évènements. Pour ce faire, la commande git log est l’outil le
plus basique et le plus puissant.
Les exemples qui suivent utilisent un projet très simple nommé
simplegit utilisé pour les démonstrations. Pour récupérer le projet,
lancez :
git clone https://github.com/schacon/simplegit-progit
Lorsque vous lancez git log dans le répertoire de ce projet, vous
devriez obtenir un résultat qui ressemble à ceci :
$ git log
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar 17 21:52:11 2008 -0700
changed the version number
commit 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar 15 16:40:33 2008 -0700
removed unnecessary test
commit a11bef06a3f659402fe7563abf99ad00de2209e6
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar 15 10:31:28 2008 -0700
first commit
Par défaut, git log invoqué sans argument énumère en ordre
chronologique inversé les commits réalisés. Cela signifie que les
commits les plus récents apparaissent en premier. Comme vous le
remarquez, cette commande indique chaque commit avec sa somme de
contrôle SHA-1, le nom et l’e-mail de l’auteur, la date et le message du
commit.
git log dispose d’un très grand nombre d’options permettant de
paramétrer exactement ce que l’on cherche à voir. Nous allons détailler
quelques-unes des plus utilisées.
Une des options les plus utiles est -p, qui montre les différences
introduites entre chaque validation. Vous pouvez aussi utiliser -2 qui
limite la sortie de la commande aux deux entrées les plus récentes :
$ git log -p -2
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar 17 21:52:11 2008 -0700
changed the version number
diff --git a/Rakefile b/Rakefile
index a874b73..8f94139 100644
--- a/Rakefile
+++ b/Rakefile
@@ -5,7 +5,7 @@ require 'rake/gempackagetask'
spec = Gem::Specification.new do |s|
s.platform = Gem::Platform::RUBY
s.name = "simplegit"
- s.version = "0.1.0"
+ s.version = "0.1.1"
s.author = "Scott Chacon"
s.email = "schacon@gee-mail.com"
s.summary = "A simple gem for using Git in Ruby code."
commit 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar 15 16:40:33 2008 -0700
removed unnecessary test
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index a0a60ae..47c6340 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -18,8 +18,3 @@ class SimpleGit
end
end
-
-if $0 == __FILE__
- git = SimpleGit.new
- puts git.show
-end
\ No newline at end of file
Cette option affiche la même information mais avec un diff suivant directement chaque entrée. C’est très utile pour des revues de code ou pour naviguer rapidement à travers l’historique des modifications qu’un collaborateur a apportées.
Vous pouvez aussi utiliser une liste d’options de résumé avec git log.
Par exemple, si vous souhaitez visualiser des statistiques résumées pour
chaque commit, vous pouvez utiliser l’option --stat :
$ git log --stat
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar 17 21:52:11 2008 -0700
changed the version number
Rakefile | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
commit 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar 15 16:40:33 2008 -0700
removed unnecessary test
lib/simplegit.rb | 5 -----
1 file changed, 5 deletions(-)
commit a11bef06a3f659402fe7563abf99ad00de2209e6
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar 15 10:31:28 2008 -0700
first commit
README | 6 ++++++
Rakefile | 23 +++++++++++++++++++++++
lib/simplegit.rb | 25 +++++++++++++++++++++++++
3 files changed, 54 insertions(+)
Comme vous pouvez le voir, l’option --stat affiche sous chaque entrée
de validation une liste des fichiers modifiés, combien de fichiers ont
été changés et combien de lignes ont été ajoutées ou retirées dans ces
fichiers. Elle ajoute un résumé des informations en fin de sortie. Une
autre option utile est --pretty. Cette option modifie le journal vers
un format différent. Quelques options incluses sont disponibles.
L’option oneline affiche chaque commit sur une seule ligne, ce qui
peut s’avérer utile lors de la revue d’un long journal. En complément,
les options short (court), full (complet) et fuller (plus complet)
montrent le résultat à peu de choses près dans le même format mais avec
plus ou moins d’informations :
$ git log --pretty=oneline
ca82a6dff817ec66f44342007202690a93763949 changed the version number
085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 removed unnecessary test
a11bef06a3f659402fe7563abf99ad00de2209e6 first commit
L’option la plus intéressante est format qui permet de décrire
précisément le format de sortie. C’est spécialement utile pour générer
des sorties dans un format facile à analyser par une machine — lorsqu’on
spécifie intégralement et explicitement le format, on s’assure qu’il ne
changera pas au gré des mises à jour de Git :
$ git log --pretty=format:"%h - %an, %ar : %s"
ca82a6d - Scott Chacon, 6 years ago : changed the version number
085bb3b - Scott Chacon, 6 years ago : removed unnecessary test
a11bef0 - Scott Chacon, 6 years ago : first commit
Options utiles pour git log --pretty=format liste
les options de formatage les plus utiles.
| Option | Description du formatage |
|---|---|
|
Somme de contrôle du commit |
|
Somme de contrôle abrégée du commit |
|
Somme de contrôle de l’arborescence |
|
Somme de contrôle abrégée de l’arborescence |
|
Sommes de contrôle des parents |
|
Sommes de contrôle abrégées des parents |
|
Nom de l’auteur |
|
E-mail de l’auteur |
|
Date de l’auteur (au format de l’option -date=) |
|
Date relative de l’auteur |
|
Nom du validateur |
|
E-mail du validateur |
|
Date du validateur |
|
Date relative du validateur |
|
Sujet |
Vous pourriez vous demander quelle est la différence entre auteur et validateur. L'auteur est la personne qui a réalisé initialement le travail, alors que le validateur est la personne qui a effectivement validé ce travail en gestion de version. Donc, si quelqu’un envoie un patch à un projet et un des membres du projet l’applique, les deux personnes reçoivent le crédit — l’écrivain en tant qu’auteur, et le membre du projet en tant que validateur. Nous traiterons plus avant de cette distinction dans le Git distribué.
Les options oneline et format sont encore plus utiles avec une autre
option log appelée --graph. Cette option ajoute un joli graphe en
caractères ASCII pour décrire l’historique des branches et fusions :
$ git log --pretty=format:"%h %s" --graph
* 2d3acf9 ignore errors from SIGCHLD on trap
* 5e3ee11 Merge branch 'master' of git://github.com/dustin/grit
|\
| * 420eac9 Added a method for getting the current branch.
* | 30e367c timeout code and tests
* | 5a09431 add timeout protection to grit
* | e1193f8 support for heads with slashes in them
|/
* d6016bc require time for xmlschema
* 11d191e Merge branch 'defunkt' into local
Ces options deviendront plus intéressantes quand nous aborderons les branches et les fusions dans le prochain chapitre.
Les options ci-dessus ne sont que des options simples de format de
sortie de git log — il y en a de nombreuses autres. Options usuelles
de git log donne une liste des options que nous avons
traitées ainsi que d’autres options communément utilisées accompagnées
de la manière dont elles modifient le résultat de la commande log.
| Option | Description |
|---|---|
|
Affiche le patch appliqué par chaque commit |
|
Affiche les statistiques de chaque fichier pour chaque commit |
|
N’affiche que les ligne modifiées/insérées/effacées de l’option --stat |
|
Affiche la liste des fichiers modifiés après les informations du commit |
|
Affiche la liste des fichiers affectés accompagnés des informations d’ajout/modification/suppression |
|
N’affiche que les premiers caractères de la somme de contrôle SHA-1 |
|
Affiche la date en format relatif (par exemple "2 weeks ago" : il y a deux semaines) au lieu du format de date complet |
|
Affiche en caractères ASCII le graphe de branches et fusions en vis-à-vis de l’historique |
|
Affiche les commits dans un format alternatif. Les formats incluent |
|
Option de convenance correspondant à |
Limiter la longueur de l’historique
En complément des options de formatage de sortie, git log est pourvu
de certaines options de limitation utiles — des options qui permettent
de restreindre la liste à un sous-ensemble de commits. Vous avez déjà
vu une de ces options — l’option -2 qui ne montre que les deux
derniers commits. En fait, on peut utiliser -<n>, où n correspond
au nombre de commits que l’on cherche à visualiser en partant des plus
récents. En vérité, il est peu probable que vous utilisiez cette option,
parce que Git injecte par défaut sa sortie dans un outil de pagination
qui permet de la visualiser page à page.
Cependant, les options de limitation portant sur le temps, telles que
--since (depuis) et --until (jusqu’à) sont très utiles. Par exemple,
la commande suivante affiche la liste des commits des deux dernières
semaines :
$ git log --since=2.weeks
Cette commande fonctionne avec de nombreux formats — vous pouvez indiquer une date spécifique (2008-01-05) ou une date relative au présent telle que "2 years 1 day 3 minutes ago".
Vous pouvez aussi restreindre la liste aux commits vérifiant certains
critères de recherche. L’option --author permet de filtrer sur un
auteur spécifique, et l’option --grep permet de chercher des mots clés
dans les messages de validation. Notez que si vous spécifiez à la fois
--author et --grep, la commande retournera seulement des commits
correspondant simultanément aux deux critères.
Si vous souhaitez spécifier plusieurs options --grep, vous devez
ajouter l’option --all-match, car par défaut ces commandes retournent
les commits vérifiant au moins un critère de recherche.
Un autre filtre vraiment utile est l’option -S qui prend une chaîne de
caractères et ne retourne que les commits qui introduisent des
modifications qui ajoutent ou retirent du texte comportant cette chaîne.
Par exemple, si vous voulez trouver la dernière validation qui a ajouté
ou retiré une référence à une fonction spécifique, vous pouvez lancer :
$ git log -Snom_de_fonction
La dernière option vraiment utile à git log est la spécification d’un
chemin. Si un répertoire ou un nom de fichier est spécifié, le journal
est limité aux commits qui ont introduit des modifications aux
fichiers concernés. C’est toujours la dernière option de la commande,
souvent précédée de deux tirets (--) pour séparer les chemins des
options précédentes.
Le tableau Options pour limiter la sortie de git log
récapitule les options que nous venons de voir ainsi que quelques autres
pour référence.
| Option | Description |
|---|---|
|
N’affiche que les n derniers commits |
|
Limite l’affichage aux commits réalisés après la date spécifiée |
|
Limite l’affichage aux commits réalisés avant la date spécifiée |
|
Ne montre que les commits dont le champ auteur correspond à la chaîne passée en argument |
|
Ne montre que les commits dont le champ validateur correspond à la chaîne passée en argument |
|
Ne montre que les commits dont le message de validation contient la chaîne de caractères |
|
Ne montre que les commits dont les ajouts ou retraits contient la chaîne de caractères |
Par exemple, si vous souhaitez visualiser quels commits modifiant les fichiers de test dans l’historique du code source de Git ont été validés par Junio C Hamano et n’étaient pas des fusions durant le mois d’octobre 2008, vous pouvez lancer ce qui suit :
$ git log --pretty="%h - %s" --author='Junio C Hamano' --since="2008-10-01" \
--before="2008-11-01" --no-merges -- t/
5610e3b - Fix testcase failure when extended attributes are in use
acd3b9e - Enhance hold_lock_file_for_{update,append}() API
f563754 - demonstrate breakage of detached checkout with symbolic link HEAD
d1a43f2 - reset --hard/read-tree --reset -u: remove unmerged new paths
51a94af - Fix "checkout --track -b newbranch" on detached HEAD
b0ad11e - pull: allow "git pull origin $something:$current_branch" into an unborn branch
À partir des 40 000 commits constituant l’historique des sources de Git, cette commande extrait les 6 qui correspondent aux critères.
Annuler des actions
À tout moment, vous pouvez désirer annuler une de vos dernières actions. Dans cette section, nous allons passer en revue quelques outils de base permettant d’annuler des modifications. Il faut être très attentif car certaines de ces annulations sont définitives (elles ne peuvent pas être elles-mêmes annulées). C’est donc un des rares cas d’utilisation de Git où des erreurs de manipulation peuvent entraîner des pertes définitives de données.
Une des annulations les plus communes apparaît lorsqu’on valide une
modification trop tôt en oubliant d’ajouter certains fichiers, ou si on
se trompe dans le message de validation. Si vous souhaitez rectifier
cette erreur, vous pouvez valider le complément de modification avec
l’option --amend :
$ git commit --amend
Cette commande prend en compte la zone d’index et l’utilise pour le commit. Si aucune modification n’a été réalisée depuis la dernière validation (par exemple en lançant cette commande immédiatement après la dernière validation), alors l’instantané sera identique et la seule modification à introduire sera le message de validation.
L’éditeur de message de validation démarre, mais il contient déjà le message de la validation précédente. Vous pouvez éditer ce message normalement, mais il écrasera le message de la validation précédente.
Par exemple, si vous validez une version puis réalisez que vous avez oublié d’indexer les modifications d’un fichier que vous vouliez ajouter à ce commit, vous pouvez faire quelque chose comme ceci :
$ git commit -m 'validation initiale'
$ git add fichier_oublie
$ git commit --amend
Vous n’aurez au final qu’un unique commit — la seconde validation remplace le résultat de la première.
Désindexer un fichier déjà indexé
Les deux sections suivantes démontrent comment bricoler les
modifications dans votre zone d’index et votre zone de travail. Un point
sympathique est que la commande permettant de connaître l’état de ces
deux zones vous rappelle aussi comment annuler les modifications. Par
exemple, supposons que vous avez modifié deux fichiers et voulez les
valider comme deux modifications indépendantes, mais que vous avez tapé
accidentellement git add * et donc indexé les deux. Comment annuler
l’indexation d’un des fichiers ? La commande git status vous le
rappelle :
$ git add .
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
renommé : README.md -> README
modifié : CONTRIBUTING.md
Juste sous le texte « Modifications qui seront validées », elle vous
indique d’utiliser git reset HEAD <fichier>... pour désindexer un
fichier. Utilisons donc ce conseil pour désindexer le fichier
CONTRIBUTING.md :
$ git reset HEAD CONTRIBUTING.md
Modifications non indexées après reset :
M CONTRIBUTING.md
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
renommé : README.md -> README
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : CONTRIBUTING.md
La commande à taper peut sembler étrange mais elle fonctionne. Le
fichier CONTRIBUTING.md est modifié mais de retour à l’état non
indexé.
Bien que |
Pour l’instant, cette invocation magique est la seule à connaître pour
la commande git reset. Nous entrerons plus en détail sur ce que
reset réalise et comment le maîtriser pour faire des choses
intéressantes dans Reset démystifié
Réinitialiser un fichier modifié
Que faire si vous réalisez que vous ne souhaitez pas conserver les
modifications du fichier CONTRIBUTING.md ? Comment le réinitialiser
facilement, le ramener à son état du dernier instantané (ou lors du
clonage, ou dans l’état dans lequel vous l’avez obtenu dans votre copie
de travail) ? Heureusement, git status vous indique comment procéder.
Dans le résultat de la dernière commande, la zone de travail ressemble à
ceci :
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : CONTRIBUTING.md
Ce qui vous indique de façon explicite comment annuler des modifications que vous avez faites. Faisons comme indiqué :
$ git checkout -- CONTRIBUTING.md
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
renommé : README.md -> README
Vous pouvez constater que les modifications ont été annulées.
Vous devriez aussi vous apercevoir que c’est une commande dangereuse : toutes les modifications que vous auriez réalisées sur ce fichier ont disparu — vous venez tout juste de l’écraser avec un autre fichier. N’utilisez jamais cette commande à moins d’être vraiment sûr de ne pas vouloir de ces modifications. |
Si vous souhaitez seulement écarter momentanément cette modification, nous verrons comment mettre de côté et créer des branches dans le chapitre Les branches avec Git ; ce sont de meilleures façons de procéder.
Souvenez-vous, tout ce qui a été validé dans Git peut quasiment
toujours être récupéré. Y compris des commits sur des branches qui ont
été effacées ou des commits qui ont été écrasés par une validation
avec l’option --amend (se référer au chapitre Récupération de
données pour la récupération de données). Cependant,
tout ce que vous perdez avant de l’avoir validé n’a aucune chance d’être
récupérable via Git.
Travailler avec des dépôts distants
Pour pouvoir collaborer sur un projet Git, il est nécessaire de savoir comment gérer les dépôts distants. Les dépôts distants sont des versions de votre projet qui sont hébergées sur Internet ou le réseau d’entreprise. Vous pouvez en avoir plusieurs, pour lesquels vous pouvez avoir des droits soit en lecture seule, soit en lecture/écriture. Collaborer avec d’autres personnes consiste à gérer ces dépôts distants, en poussant ou tirant des données depuis et vers ces dépôts quand vous souhaitez partager votre travail. Gérer des dépôts distants inclut savoir comment ajouter des dépôts distants, effacer des dépôts distants qui ne sont plus valides, gérer des branches distantes et les définir comme suivies ou non, et plus encore. Dans cette section, nous traiterons des commandes de gestion distante.
Afficher les dépôts distants
Pour visualiser les serveurs distants que vous avez enregistrés, vous
pouvez lancer la commande git remote. Elle liste les noms des
différentes références distantes que vous avez spécifiées. Si vous avez
cloné un dépôt, vous devriez au moins voir l’origine origin —
c’est-à-dire le nom par défaut que Git donne au serveur à partir duquel
vous avez cloné :
$ git clone https://github.com/schacon/ticgit
Clonage dans 'ticgit'...
remote: Counting objects: 1857, done.
remote: Total 1857 (delta 0), reused 0 (delta 0)
Réception d'objets: 100% (1857/1857), 374.35 KiB | 243.00 KiB/s, fait.
Résolution des deltas: 100% (772/772), fait.
Vérification de la connectivité... fait.
$ cd ticgit
$ git remote
origin
Vous pouvez aussi spécifier -v, qui vous montre l’URL que Git a
stockée pour chaque nom court :
$ git remote -v
origin https://github.com/schacon/ticgit (fetch)
origin https://github.com/schacon/ticgit (push)
Si vous avez plus d’un dépôt distant, la commande précédente les liste tous. Par exemple, un dépôt avec plusieurs dépôts distants permettant de travailler avec quelques collaborateurs pourrait ressembler à ceci.
$ cd grit
$ git remote -v
bakkdoor https://github.com/bakkdoor/grit (fetch)
bakkdoor https://github.com/bakkdoor/grit (push)
cho45 https://github.com/cho45/grit (fetch)
cho45 https://github.com/cho45/grit (push)
defunkt https://github.com/defunkt/grit (fetch)
defunkt https://github.com/defunkt/grit (push)
koke git://github.com/koke/grit.git (fetch)
koke git://github.com/koke/grit.git (push)
origin git@github.com:mojombo/grit.git (fetch)
origin git@github.com:mojombo/grit.git (push)
Notez que ces dépôts distants sont accessibles au moyen de différents protocoles ; nous traiterons des protocoles au chapitre Installation de Git sur un serveur.
Ajouter des dépôts distants
J’ai expliqué et donné des exemples d’ajout de dépôts distants dans les
chapitres précédents, mais voici spécifiquement comment faire. Pour
ajouter un nouveau dépôt distant Git comme nom court auquel il est
facile de faire référence, lancez git remote add [nomcourt] [url] :
$ git remote
origin
$ git remote add pb https://github.com/paulboone/ticgit
$ git remote -v
origin https://github.com/schacon/ticgit (fetch)
origin https://github.com/schacon/ticgit (push)
pb https://github.com/paulboone/ticgit (fetch)
pb https://github.com/paulboone/ticgit (push)
Maintenant, vous pouvez utiliser le mot-clé pb sur la ligne de
commande au lieu de l’URL complète. Par exemple, si vous voulez
récupérer toute l’information que Paul a mais que vous ne souhaitez pas
l’avoir encore dans votre branche, vous pouvez lancer git fetch pb :
$ git fetch pb
remote: Counting objects: 43, done.
remote: Compressing objects: 100% (36/36), done.
remote: Total 43 (delta 10), reused 31 (delta 5)
Dépaquetage des objets: 100% (43/43), fait.
Depuis https://github.com/paulboone/ticgit
* [nouvelle branche] master -> pb/master
* [nouvelle branche] ticgit -> pb/ticgit
La branche master de Paul est accessible localement en tant que
pb/master — vous pouvez la fusionner dans une de vos propres branches,
ou vous pouvez extraire une branche localement si vous souhaitez
l’inspecter. Nous traiterons plus en détail de la nature des branches et
de leur utilisation au chapitre Les branches avec
Git.
Récupérer et tirer depuis des dépôts distants
Comme vous venez tout juste de le voir, pour obtenir les données des dépôts distants, vous pouvez lancer :
$ git fetch [remote-name]
Cette commande s’adresse au dépôt distant et récupère toutes les données de ce projet que vous ne possédez pas déjà. Après cette action, vous possédez toutes les références à toutes les branches contenues dans ce dépôt, que vous pouvez fusionner ou inspecter à tout moment.
Si vous clonez un dépôt, le dépôt distant est automatiquement ajouté
sous le nom « origin ». Donc, git fetch origin récupère tout ajout qui
a été poussé vers ce dépôt depuis que vous l’avez cloné ou la dernière
fois que vous avez récupéré les ajouts. Il faut noter que la commande
fetch tire les données dans votre dépôt local mais sous sa propre
branche — elle ne les fusionne pas automatiquement avec aucun de vos
travaux ni ne modifie votre copie de travail. Vous devez volontairement
fusionner ses modifications distantes dans votre travail lorsque vous le
souhaitez.
Si vous avez créé une branche pour suivre l’évolution d’une branche
distante (cf. la section suivante et le chapitre Les branches avec
Git pour plus d’information), vous pouvez utiliser
la commande git pull qui récupère et fusionne automatiquement une
branche distante dans votre branche locale. Ce comportement peut
correspondre à une méthode de travail plus confortable, sachant que par
défaut la commande git clone paramètre votre branche locale pour
qu’elle suive la branche master du dépôt que vous avez cloné (en
supposant que le dépôt distant ait une branche master). Lancer
git pull récupère généralement les données depuis le serveur qui a été
initialement cloné et essaie de les fusionner dans votre branche de
travail actuel.
Pousser son travail sur un dépôt distant
Lorsque votre dépôt vous semble prêt à être partagé, il faut le pousser
en amont. La commande pour le faire est simple :
git push [nom-distant] [nom-de-branche]. Si vous souhaitez pousser
votre branche master vers le serveur origin (pour rappel, cloner un
dépôt définit automatiquement ces noms pour vous), alors vous pouvez
lancer ceci pour pousser votre travail vers le serveur amont :
$ git push origin master
Cette commande ne fonctionne que si vous avez cloné depuis un serveur sur lequel vous avez des droits d’accès en écriture et si personne n’a poussé dans l’intervalle. Si vous et quelqu’un d’autre clonez un dépôt au même moment et que cette autre personne pousse ses modifications et qu’après vous tentez de pousser les vôtres, votre poussée sera rejetée à juste titre. Vous devrez tout d’abord tirer les modifications de l’autre personne et les fusionner avec les vôtres avant de pouvoir pousser. Référez-vous au chapitre Les branches avec Git pour de plus amples informations sur les techniques pour pousser vers un serveur distant.
Inspecter un dépôt distant
Si vous souhaitez visualiser plus d’informations à propos d’un dépôt
distant particulier, vous pouvez utiliser la commande
git remote show [nom-distant]. Si vous lancez cette commande avec un
nom court particulier, tel que origin, vous obtenez quelque chose
comme :
$ git remote show origin
* distante origin
URL de rapatriement : https://github.com/schacon/ticgit
URL push : https://github.com/schacon/ticgit
Branche HEAD : master
Branches distantes :
master suivi
ticgit suivi
Branche locale configurée pour 'git pull' :
master fusionne avec la distante master
Référence locale configurée pour 'git push' :
master pousse vers master (à jour)
Cela donne la liste des URL pour le dépôt distant ainsi que la liste des
branches distantes suivies. Cette commande vous informe que si vous êtes
sur la branche master et si vous lancez git pull, il va
automatiquement fusionner la branche master du dépôt distant après
avoir récupéré toutes les références sur le serveur distant. Cela donne
aussi la liste des autres références qu’il aura tirées.
Le résultat ci-dessus est un exemple simple mais réaliste de dépôt
distant. Lors d’une utilisation plus intense de Git, la commande
git remote show fournira beaucoup d’information :
$ git remote show origin
* distante origin
URL: https://github.com/my-org/complex-project
URL de rapatriement : https://github.com/my-org/complex-project
URL push : https://github.com/my-org/complex-project
Branche HEAD : master
Branches distantes :
master suivi
dev-branch suivi
markdown-strip suivi
issue-43 nouveau (le prochain rapatriement (fetch) stockera dans remotes/origin)
issue-45 nouveau (le prochain rapatriement (fetch) stockera dans remotes/origin)
refs/remotes/origin/issue-11 dépassé (utilisez 'git remote prune' pour supprimer)
Branches locales configurées pour 'git pull' :
dev-branch fusionne avec la distante dev-branch
master fusionne avec la distante master
Références locales configurées pour 'git push' :
dev-branch pousse vers dev-branch (à jour)
markdown-strip pousse vers markdown-strip (à jour)
master pousse vers master (à jour)
Cette commande affiche les branches poussées automatiquement lorsqu’on
lance git push dessus. Elle montre aussi les branches distantes qui
n’ont pas encore été rapatriées, les branches distantes présentes
localement mais effacées sur le serveur, et toutes les branches qui
seront fusionnées quand on lancera git pull.
Retirer et renommer des dépôts distants
Si vous souhaitez renommer une référence, vous pouvez lancer
git remote rename pour modifier le nom court d’un dépôt distant. Par
exemple, si vous souhaitez renommer pb en paul, vous pouvez le faire
avec git remote rename :
$ git remote rename pb paul
$ git remote
origin
paul
Il faut mentionner que ceci modifie aussi les noms de branches
distantes. Celle qui était référencée sous pb/master l’est maintenant
sous paul/master.
Si vous souhaitez retirer un dépôt distant pour certaines raisons — vous
avez changé de serveur ou vous n’utilisez plus ce serveur particulier,
ou peut-être un contributeur a cessé de contribuer — vous pouvez
utiliser git remote rm :
$ git remote rm paul
$ git remote
origin
Étiquetage
À l’instar de la plupart des VCS, Git donne la possibilité d’étiqueter
un certain état dans l’historique comme important. Généralement, les
gens utilisent cette fonctionnalité pour marquer les états de
publication (v1.0 et ainsi de suite). Dans cette section, nous
apprendrons comment lister les différentes étiquettes (tag en
anglais), comment créer de nouvelles étiquettes et les différents types
d’étiquettes.
Lister vos étiquettes
Lister les étiquettes existantes dans Git est très simple. Tapez juste
git tag :
$ git tag
v0.1
v1.3
Cette commande liste les étiquettes dans l’ordre alphabétique. L’ordre dans lequel elles apparaissent n’a aucun rapport avec l’historique.
Vous pouvez aussi rechercher les étiquettes correspondant à un motif particulier. Par exemple, le dépôt des sources de Git contient plus de 500 étiquettes. Si vous souhaitez ne visualiser que les séries 1.8.5, vous pouvez lancer ceci :
$ git tag -l 'v1.8.5*'
v1.8.5
v1.8.5-rc0
v1.8.5-rc1
v1.8.5-rc2
v1.8.5-rc3
v1.8.5.1
v1.8.5.2
v1.8.5.3
v1.8.5.4
v1.8.5.5
Créer des étiquettes
Git utilise deux types principaux d’étiquettes : légères et annotées.
Une étiquette légère ressemble beaucoup à une branche qui ne change pas, c’est juste un pointeur sur un commit spécifique.
Les étiquettes annotées, par contre, sont stockées en tant qu’objets à part entière dans la base de données de Git. Elles ont une somme de contrôle, contiennent le nom et l’adresse e-mail du créateur, la date, un message d’étiquetage et peuvent être signées et vérifiées avec GNU Privacy Guard (GPG). Il est généralement recommandé de créer des étiquettes annotées pour générer toute cette information mais si l’étiquette doit rester temporaire ou l’information supplémentaire n’est pas désirée, les étiquettes légères peuvent suffire.
Les étiquettes annotées
Créer des étiquettes annotées est simple avec Git. Le plus simple est de
spécifier l’option -a à la commande tag :
$ git tag -a v1.4 -m 'ma version 1.4'
$ git tag
v0.1
v1.3
v1.4
L’option -m permet de spécifier le message d’étiquetage qui sera
stocké avec l’étiquette. Si vous ne spécifiez pas de message en ligne
pour une étiquette annotée, Git lance votre éditeur pour pouvoir le
saisir.
Vous pouvez visualiser les données de l’étiquette à côté du commit qui
a été marqué en utilisant la commande git show :
$ git show v1.4
tag v1.4
Tagger: Ben Straub <ben@straub.cc>
Date: Sat May 3 20:19:12 2014 -0700
ma version 1.4
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar 17 21:52:11 2008 -0700
changed the version number
Cette commande affiche le nom du créateur, la date de création de l’étiquette et le message d’annotation avant de montrer effectivement l’information de validation.
Les étiquettes légères
Une autre manière d’étiqueter les commits est d’utiliser les
étiquettes légères. Celles-ci se réduisent à stocker la somme de
contrôle d’un commit dans un fichier, aucune autre information n’est
conservée. Pour créer une étiquette légère, il suffit de n’utiliser
aucune des options -a, -s ou -m :
$ git tag v1.4-lg
$ git tag
v0.1
v1.3
v1.4
v1.4-lg
v1.5
Cette fois-ci, en lançant git show sur l’étiquette, on ne voit plus
aucune information complémentaire. La commande ne montre que
l’information de validation :
$ git show v1.4-lg
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar 17 21:52:11 2008 -0700
changed the version number
Étiqueter après coup
Vous pouvez aussi étiqueter des commits plus anciens. Supposons que l’historique des commits ressemble à ceci :
$ git log --pretty=oneline
15027957951b64cf874c3557a0f3547bd83b3ff6 Fusion branche 'experimental'
a6b4c97498bd301d84096da251c98a07c7723e65 Début de l'écriture support
0d52aaab4479697da7686c15f77a3d64d9165190 Un truc de plus
6d52a271eda8725415634dd79daabbc4d9b6008e Fusion branche 'experimental'
0b7434d86859cc7b8c3d5e1dddfed66ff742fcbc ajout d'une fonction de validatn
4682c3261057305bdd616e23b64b0857d832627b ajout fichier afaire
166ae0c4d3f420721acbb115cc33848dfcc2121a début de l'ecriture support
9fceb02d0ae598e95dc970b74767f19372d61af8 mise à jour rakefile
964f16d36dfccde844893cac5b347e7b3d44abbc validation afaire
8a5cbc430f1a9c3d00faaeffd07798508422908a mise à jour lisezmoi
Maintenant, supposons que vous avez oublié d’étiqueter le projet à la
version v1.2 qui correspondait au commit « mise à jour rakefile ».
Vous pouvez toujours le faire après l’évènement. Pour étiqueter ce
commit, vous spécifiez la somme de contrôle du commit (ou une
partie) en fin de commande :
$ git tag -a v1.2 9fceb02
Le commit a été étiqueté :
$ git tag
v0.1
v1.2
v1.3
v1.4
v1.4-lg
v1.5
$ git show v1.2
tag v1.2
Tagger: Scott Chacon <schacon@gee-mail.com>
Date: Mon Feb 9 15:32:16 2009 -0800
version 1.2
commit 9fceb02d0ae598e95dc970b74767f19372d61af8
Author: Magnus Chacon <mchacon@gee-mail.com>
Date: Sun Apr 27 20:43:35 2008 -0700
updated rakefile
...
Partager les étiquettes
Par défaut, la commande git push ne transfère pas les étiquettes vers
les serveurs distants. Il faut explicitement pousser les étiquettes
après les avoir créées localement. Ce processus s’apparente à pousser
des branches distantes — vous pouvez lancer
git push origin [nom-du-tag].
$ git push origin v1.5
Décompte des objets: 14, fait.
Delta compression using up to 8 threads.
Compression des objets: 100% (12/12), fait.
Écriture des objets: 100% (14/14), 2.05KiB | 0 bytes/s, fait.
Total 14 (delta 3), reused 0 (delta 0)
To git@github.com:schacon/simplegit.git
* [new tag] v1.5 -> v1.5
Si vous avez de nombreuses étiquettes que vous souhaitez pousser en une
fois, vous pouvez aussi utiliser l’option --tags avec la commande
git push. Ceci transférera toutes les nouvelles étiquettes vers le
serveur distant.
$ git push origin --tags
Décompte des objets: 1, fait.
Écriture des objets: 100% (1/1), 160 bytes | 0 bytes/s, fait.
Total 1 (delta 0), reused 0 (delta 0)
To git@github.com:schacon/simplegit.git
* [new tag] v1.4 -> v1.4
* [new tag] v1.4-lg -> v1.4-lg
À présent, lorsqu’une autre personne clone ou tire depuis votre dépôt, elle obtient aussi les étiquettes.
Extraire une étiquette
Il n’est pas vraiment possible d’extraire une étiquette avec Git, puisque les étiquettes ne peuvent pas être modifiées. Si vous souhaitez ressortir dans votre copie de travail une version de votre dépôt correspondant à une étiquette spécifique, le plus simple consiste à créer une branche à partir de cette étiquette :
$ git checkout -b version2 v2.0.0
Extraction des fichiers: 100% (602/602), fait.
Basculement sur la nouvelle branche 'version2'
Bien sûr, toute validation modifiera la branche version2 par rapport à
l’étiquette v2.0.0 puisqu’elle avancera avec les nouvelles
modifications. Soyez donc prudent sur l’identification de cette branche.
Les alias Git
Avant de clore ce chapitre sur les bases de Git, il reste une astuce qui peut rendre votre apprentissage de Git plus simple, facile ou familier : les alias. Nous n’y ferons pas référence ni ne les considèrerons utilisés dans la suite du livre, mais c’est un moyen de facilité qui mérite d’être connu.
Git ne complète pas votre commande si vous ne la tapez que
partiellement. Si vous ne voulez pas avoir à taper l’intégralité du
texte de chaque commande, vous pouvez facilement définir un alias pour
chaque commande en utilisant git config. Voici quelques exemples qui
pourraient vous intéresser :
$ git config --global alias.co checkout
$ git config --global alias.br branch
$ git config --global alias.ci commit
$ git config --global alias.st status
Ceci signifie que, par exemple, au lieu de taper git commit, vous
n’avez plus qu’à taper git ci. Au fur et à mesure de votre utilisation
de Git, vous utiliserez probablement d’autres commandes plus
fréquemment. Dans ce cas, n’hésitez pas à créer de nouveaux alias.
Cette technique peut aussi être utile pour créer des commandes qui vous manquent. Par exemple, pour corriger le problème d’ergonomie que vous avez rencontré lors de la désindexation d’un fichier, vous pourriez créer un alias pour désindexer :
$ git config --global alias.unstage 'reset HEAD --'
Cela rend les deux commandes suivantes équivalentes :
$ git unstage fileA
$ git reset HEAD fileA
Cela rend les choses plus claires. Il est aussi commun d’ajouter un
alias last, de la manière suivante :
$ git config --global alias.last 'log -1 HEAD'
Ainsi, vous pouvez visualiser plus facilement le dernier commit :
$ git last
commit 66938dae3329c7aebe598c2246a8e6af90d04646
Author: Josh Goebel <dreamer3@example.com>
Date: Tue Aug 26 19:48:51 2008 +0800
test for current head
Signed-off-by: Scott Chacon <schacon@example.com>
Pour explication, Git remplace simplement la nouvelle commande par tout
ce que vous lui aurez demandé d’aliaser. Si par contre vous souhaitez
lancer une commande externe plutôt qu’une sous-commande Git, vous pouvez
commencer votre commande par un caractère !. C’est utile si vous
écrivez vos propres outils pour travailler dans un dépôt Git. On peut
par exemple aliaser git visual pour lancer gitk :
$ git config --global alias.visual "!gitk"
Résumé
À présent, vous pouvez réaliser toutes les opérations locales de base de Git — créer et cloner un dépôt, faire des modifications, les indexer et les valider, visualiser l’historique de ces modifications. Au prochain chapitre, nous traiterons de la fonctionnalité unique de Git : son modèle de branches.