Utilitaires Git
- Sélection des versions
- Indexation interactive
- Remisage et nettoyage
- Signer votre travail
- Recherche
- Réécrire l’historique
- Reset démystifié
- Fusion avancée
- Rerere
- Déboguer avec Git
- Sous-modules
- Empaquetage (bundling)
- Replace
- Stockage des identifiants
- Résumé
À présent, vous avez appris les commandes et modes de fonctionnement usuels requis pour gérer et maintenir un dépôt Git pour la gestion de votre code source. Vous avez déroulé les routines de suivi et de validation de fichiers, vous avez exploité la puissance de l’index, de la création et de la fusion de branches locales de travail.
Maintenant, vous allez explorer un certain nombre de fonctionnalités particulièrement efficaces, fonctionnalités que vous utiliserez moins souvent mais dont vous pourriez avoir l’usage à un moment ou à un autre.
Sélection des versions
Git vous permet de faire référence à certains commits ou un ensemble de commits de différentes façons. Si elles ne sont pas toutes évidentes, il est bon de les connaître.
Révisions ponctuelles
Naturellement, vous pouvez référencer un commit par sa signature SHA-1, mais il existe des méthodes plus confortables pour les humains. Cette section présente les méthodes pour référencer un commit simple.
Empreinte SHA courte
Git est capable de deviner de quel commit vous parlez si vous ne fournissez que quelques caractères du début de la signature, tant que votre SHA-1 partiel comporte au moins 4 caractères et ne correspond pas à plusieurs commits. Dans ces conditions, un seul objet correspondra à ce SHA-1 partiel.
Par exemple, pour afficher un commit précis, supposons que vous
exécutiez git log et que vous identifiiez le commit où vous avez
introduit une fonctionnalité précise.
$ git log
commit 734713bc047d87bf7eac9674765ae793478c50d3
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
Pour cet exemple, choisissons 1c002dd.... Si vous affichez le contenu
de ce commit via git show, les commandes suivantes sont équivalentes
(en partant du principe que les SHA-1 courts ne sont pas ambigus).
$ git show 1c002dd4b536e7479fe34593e72e6c6c1819e53b
$ git show 1c002dd4b536e7479f
$ git show 1c002d
Git peut déterminer une référence SHA-1 tout à la fois la plus courte
possible et non ambigüe. Ajoutez l’option --abbrev-commit à la
commande git log et le résultat affiché utilisera des valeurs plus
courtes mais uniques ; par défaut Git retiendra 7 caractères et
augmentera au besoin :
$ git log --abbrev-commit --pretty=oneline
ca82a6d changed the version number
085bb3b removed unnecessary test code
a11bef0 first commit
En règle générale, entre 8 et 10 caractères sont largement suffisant pour assurer l’unicité dans un projet.
Un des plus gros projets utilisant Git, le noyau Linux, est un projet plutôt important de plus de 450k commits et 3,6 millions d’objets dont les empreintes SHA sont uniques à partir des 11 premiers caractères.
Quelques mots sur SHA-1
Beaucoup de gens s’inquiètent qu’à un moment donné ils auront, par des circonstances hasardeuses, deux objets dans leur référentiel de hachage de même empreinte SHA-1. Qu’en est-il réellement ? S’il vous arrivait de valider un objet qui se hache à la même empreinte SHA-1 qu’un objet existant dans votre référentiel, Git verrait l’objet existant déjà dans votre base de données et présumerait qu’il était déjà enregistré. Si vous essayez de récupérer l’objet de nouveau à un moment donné, vous auriez toujours les données du premier objet. Quoi qu’il en soit, vous devriez être conscient à quel point ce scénario est ridiculement improbable. Une empreinte SHA-1 porte sur 20 octets soit 160 bits. Le nombre d’objets aléatoires à hacher requis pour assurer une probabilité de collision de 50 % vaut environ 280 (la formule pour calculer la probabilité de collision est Voici un exemple pour vous donner une idée de ce qui pourrait provoquer une collision du SHA-1. Si tous les 6,5 milliards d’humains sur Terre programmaient et que chaque seconde, chacun produisait du code équivalent à l’historique entier du noyau Linux (3,6 million d’objets Git) et le poussait sur un énorme dépôt Git, cela prendrait 2 ans pour que ce dépôt contienne assez d’objets pour avoir une probabilité de 50 % qu’une seule collision SHA-1 existe. Il y a une probabilité plus grande que tous les membres de votre équipe de programmation soient attaqués et tués par des loups dans des incidents sans relation la même nuit. |
Références de branches
La méthode la plus commune pour désigner un commit est une branche y
pointant. Dès lors, vous pouvez utiliser le nom de la branche dans toute
commande utilisant un objet de type commit ou un SHA-1. Par exemple,
si vous souhaitez afficher le dernier commit d’une branche, les
commandes suivantes sont équivalentes, en supposant que la branche
sujet1 pointe sur ca82a6d :
$ git show ca82a6dff817ec66f44342007202690a93763949
$ git show sujet1
Pour connaître l’empreinte SHA sur laquelle pointe une branche ou pour
savoir parmi tous les exemples précédents ce que cela donne en terme de
SHA, vous pouvez utiliser la commande de plomberie nommée rev-parse.
Référez-vous à Les tripes de Git pour plus
d’informations sur les commandes de plomberie ; rev-parse sert aux
opérations de bas niveau et n’est pas conçue pour être utilisée
quotidiennement. Quoi qu’il en soit, elle se révèle utile pour
comprendre ce qui se passe. Je vous invite à tester rev-parse sur
votre propre branche.
$ git rev-parse topic1
ca82a6dff817ec66f44342007202690a93763949
Raccourcis RefLog
Git maintient en arrière-plan un historique des références où sont passés HEAD et vos branches sur les derniers mois — ceci s’appelle le reflog.
Vous pouvez le consulter avec la commande git reflog :
$ git reflog
734713b... HEAD@{0}: commit: fixed refs handling, added gc auto, updated
d921970... HEAD@{1}: merge phedders/rdocs: Merge made by recursive.
1c002dd... HEAD@{2}: commit: added some blame and merge stuff
1c36188... HEAD@{3}: rebase -i (squash): updating HEAD
95df984... HEAD@{4}: commit: # This is a combination of two commits.
1c36188... HEAD@{5}: rebase -i (squash): updating HEAD
7e05da5... HEAD@{6}: rebase -i (pick): updating HEAD
À chaque fois que l’extrémité de votre branche est modifiée, Git
enregistre cette information pour vous dans son historique temporaire.
Vous pouvez référencer d’anciens commits avec cette donnée. Si vous
souhaitez consulter le n-ième antécédent de votre HEAD, vous pouvez
utiliser la référence @{n} du reflog, 5 dans cet exemple :
$ git show HEAD@{5}
Vous pouvez également remonter le temps et savoir où en était une
branche à une date donnée. Par exemple, pour savoir où en était la
branche master hier (yesterday en anglais), tapez :
$ git show master@{yesterday}
Cette technique fonctionne uniquement si l’information est encore présente dans le reflog et vous ne pourrez donc pas le consulter sur des commits plus vieux que quelques mois.
Pour consulter le reflog au format git log, exécutez: git log -g :
$ git log -g master
commit 734713bc047d87bf7eac9674765ae793478c50d3
Reflog: master@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: commit: fixed refs handling, added gc auto, updated
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Reflog: master@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: merge phedders/rdocs: Merge made by recursive.
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Veuillez noter que le reflog ne stocke que des informations locales,
c’est un historique de ce que vous avez fait dans votre dépôt. Les
références sont différentes pour un autre dépôt et juste après le clone
d’un dépôt, votre reflog sera vide puisque qu’aucune activité n’aura été
produite. Exécuter git show HEAD@{2.months.ago} ne fonctionnera que si
vous avez dupliqué ce projet depuis au moins 2 mois — si vous l’avez
dupliqué il y a 5 minutes, vous n’obtiendrez aucun résultat.
Références ancêtres
Une solution fréquente pour référencer un commit est d’utiliser son
ascendance. Si vous suffixez une référence par ^, Git la résoudra
comme étant le parent de cette référence. Supposons que vous consultiez
votre historique :
$ git log --pretty=format:'%h %s' --graph
* 734713b fixed refs handling, added gc auto, updated tests
* d921970 Merge commit 'phedders/rdocs'
|\
| * 35cfb2b Some rdoc changes
* | 1c002dd added some blame and merge stuff
|/
* 1c36188 ignore *.gem
* 9b29157 add open3_detach to gemspec file list
Alors, vous pouvez consulter le commit précédent en spécifiant
HEAD^, ce qui signifie « le parent de HEAD » :
$ git show HEAD^
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Vous pouvez également spécifier un nombre après ^ — par exemple,
d921970^2 signifie « le second parent de d921970 ». Cette syntaxe ne
sert que pour les commits de fusion, qui ont plus d’un parent. Le
premier parent est la branche depuis laquelle vous avez fusionné, et le
second est le commit de la branche que vous avez fusionnée :
$ git show d921970^
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
$ git show d921970^2
commit 35cfb2b795a55793d7cc56a6cc2060b4bb732548
Author: Paul Hedderly <paul+git@mjr.org>
Date: Wed Dec 10 22:22:03 2008 +0000
Some rdoc changes
Une autre solution courante pour spécifier une référence ancêtre est le
~. Il fait également référence au premier parent, donc HEAD~ et
HEAD^ sont équivalents. La différence apparaît si vous spécifiez un
nombre. HEAD~2 signifie « le premier parent du premier parent », ou
bien « le grand-parent » ; on remonte les premiers parents autant de
fois que demandé. Par exemple, dans l’historique précédemment présenté,
HEAD~3 serait :
$ git show HEAD~3
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
Cela peut aussi s’écrire HEAD^^^, qui là encore est le premier parent
du premier parent du premier parent :
$ git show HEAD^^^
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
Vous pouvez également combiner ces syntaxes — vous pouvez obtenir le
second parent de la référence précédente (en supposant que c’était un
commit de fusion) en utilisant HEAD~3^2, et ainsi de suite.
Plages de commits
À présent que vous pouvez spécifier des commits individuels, voyons comment spécifier des plages de commits. Ceci est particulièrement pratique pour la gestion des branches — si vous avez beaucoup de branches, vous pouvez utiliser les plages pour répondre à des questions telles que « Quel travail sur cette branche n’ai-je pas encore fusionné sur ma branche principale ? ».
Double point
La spécification de plage de commits la plus fréquente est la syntaxe double-point. En gros, cela demande à Git de résoudre la plage des commits qui sont accessibles depuis un commit mais ne le sont pas depuis un autre. Par exemple, disons que votre historique ressemble à Exemple d’historique pour la sélection de plage..

Figure 137. Exemple d’historique pour la sélection de plage.
Si vous voulez savoir ce qui n’a pas encore été fusionné sur votre
branche master depuis votre branche experiment, vous pouvez demander
à Git de vous montrer un journal des commits avec master..experiment
— ce qui signifie « tous les commits accessibles par experiment qui
ne le sont pas par master ». Dans un souci de brièveté et de clarté de
ces exemples, je vais utiliser les lettres des commits issus du
diagramme à la place de la vraie liste dans l’ordre où ils auraient dû
être affichés :
$ git log master..experiment
D
C
Si, par contre, vous souhaitez voir l’opposé — tous les commits dans
master mais pas encore dans experiment — vous pouvez inverser les
noms de branches, experiment..master vous montre tout ce que master
accède mais qu'experiment ne voit pas :
$ git log experiment..master
F
E
C’est pratique si vous souhaitez maintenir experiment à jour et
anticiper les fusions. Un autre cas d’utilisation fréquent consiste à
voir ce que vous vous apprêtez à pousser sur une branche distante :
$ git log origin/master..HEAD
Cette commande vous affiche tous les commits de votre branche courante
qui ne sont pas sur la branche master du dépôt distant origin. Si
vous exécutez git push et que votre branche courante suit
origin/master, les commits listés par git log origin/master..HEAD
sont les commits qui seront transférés sur le serveur. Vous pouvez
également laisser tomber une borne de la syntaxe pour faire comprendre à
Git que vous parlez de HEAD. Par exemple, vous pouvez obtenir les mêmes
résultats que précédemment en tapant git log origin/master.. — Git
utilise HEAD si une des bornes est manquante.
Emplacements multiples
La syntaxe double-point est pratique comme raccourci ; mais peut-être
souhaitez-vous utiliser plus d’une branche pour spécifier une révision,
comme pour voir quels commits sont dans plusieurs branches mais sont
absents de la branche courante. Git vous permet cela avec ^ ou --not
en préfixe de toute référence de laquelle vous ne souhaitez pas voir les
commits. Les 3 commandes ci-après sont équivalentes :
$ git log refA..refB
$ git log ^refA refB
$ git log refB --not refA
C’est utile car cela vous permet de spécifier plus de 2 références dans
votre requête, ce que vous ne pouvez accomplir avec la syntaxe
double-point. Par exemple, si vous souhaitez voir les commits qui sont
accessibles depuis refA et refB mais pas depuis refC, vous pouvez
taper ces 2 commandes :
$ git log refA refB ^refC
$ git log refA refB --not refC
Ceci vous fournit un système de requêtage des révisions très puissant, pour vous aider à saisir ce qui se trouve sur vos branches.
Triple point
La dernière syntaxe majeure de sélection de plage de commits est la
syntaxe triple-point qui spécifie tous les commits accessibles par
l’une des deux références, exclusivement. Toujours avec l’exemple
d’historique de Exemple d’historique pour la sélection de
plage., si vous voulez voir ce qui se trouve sur master
ou experiment mais pas sur les deux, exécutez :
$ git log master...experiment
F
E
D
C
Encore une fois, cela vous donne un log normal mais ne vous montre les
informations que pour ces quatre commits, dans l’ordre naturel des
dates de validation.
Une option courante à utiliser avec la commande log dans ce cas est
--left-right qui vous montre la borne de la plage à laquelle ce
commit appartient. Cela rend les données plus utiles :
$ git log --left-right master...experiment
< F
< E
> D
> C
Avec ces outils, vous pourrez spécifier à Git les commits que vous souhaitez inspecter.
Indexation interactive
Git propose quelques scripts qui rendent les opérations en ligne de
commande plus simples. Nous allons à présent découvrir des commandes
interactives vous permettant de choisir les fichiers ou les parties d’un
fichier à incorporer à un commit. Ces outils sont particulièrement
pratiques si vous modifiez un grand nombre de fichiers et que vous
souhaitez valider ces changements en modifications plus atomiques plutôt
que d’un tenant. De la sorte, vous vous assurez que vos commits sont
des ensembles cohérents de modifications et qu’ils peuvent être
facilement revus par vos collaborateurs. Si vous exécutez git add avec
l’option -i ou --interactive, Git entre en mode interactif et
affiche quelque chose comme :
$ git add -i
staged unstaged path
1: unchanged +0/-1 TODO
2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now>
Vous vous apercevrez que cette commande propose une vue bien différente
de votre index ; en gros, c’est la même information que vous auriez
obtenue avec git status mais en plus succinct et plus instructif. Cela
liste les modifications que vous avez indexées à gauche et celles hors
index à droite.
En dessous vient la section des commandes (Commands). Vous aurez accès à un certain nombre d’actions, notamment indexer des fichiers, les enlever de l’index, indexer des parties de fichiers, ajouter des fichiers non indexés, et vérifier les différences de ce que vous avez indexé.
Indexation et désindexation des fichiers
Si vous tapez 2 ou u au prompt What now>, le script vous demande
quels fichiers vous voulez indexer :
What now> 2
staged unstaged path
1: unchanged +0/-1 TODO
2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
Update>>
Pour indexer les fichiers TODO et index.html, vous pouvez taper ces nombres :
Update>> 1,2
staged unstaged path
* 1: unchanged +0/-1 TODO
* 2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
Update>>
Le caractère * au début de la ligne de chaque fichier indique que
celui-ci est sélectionné. Si vous tapez Entrée sur l’invite Update>>,
Git prend tout ce qui est sélectionné et l’indexe pour vous :
Update>>
updated 2 paths
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 1
staged unstaged path
1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
À présent, vous pouvez voir que les fichiers TODO et index.html sont
indexés (staged en anglais) et que simplegit.rb ne l’est toujours
pas. Si vous souhaitez enlever de l’index le fichier TODO, utilisez 3
(ou r pour revert en anglais) :
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 3
staged unstaged path
1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Revert>> 1
staged unstaged path
* 1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Revert>> [enter]
reverted one path
Un aperçu rapide à votre statut Git et vous pouvez voir que vous avez enlevé le fichier TODO de l’index :
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 1
staged unstaged path
1: unchanged +0/-1 TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Pour voir la modification que vous avez indexée, utilisez 6 ou d
(pour différence). Cela vous affiche la liste des fichiers indexés et
vous pouvez choisir ceux pour lesquels vous voulez consulter la
différence. C’est équivalent à git diff --cached en ligne de
commande :
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 6
staged unstaged path
1: +1/-1 nothing index.html
Review diff>> 1
diff --git a/index.html b/index.html
index 4d07108..4335f49 100644
--- a/index.html
+++ b/index.html
@@ -16,7 +16,7 @@ Date Finder
<p id="out">...</p>
-<div id="footer">contact : support@github.com</div>
+<div id="footer">contact : email.support@github.com</div>
<script type="text/javascript">
Avec ces commandes élémentaires, vous pouvez utiliser l’ajout interactif pour manipuler votre index un peu plus facilement.
Indexations partielles
Git est également capable d’indexer certaines parties d’un fichier. Par
exemple, si vous modifiez en deux endroits votre fichier simplegit.rb
et que vous souhaitez indexer une modification seulement, cela peut se
faire très aisément avec Git. En mode interactif, tapez 5 ou p (pour
patch en anglais). Git vous demandera quels fichiers vous voulez
indexer partiellement, puis, pour chacun des fichiers sélectionnés, il
affichera les parties du fichier où il y a des différences et vous
demandera si vous souhaitez les indexer, une par une :
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index dd5ecc4..57399e0 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -22,7 +22,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log -n 25 #{treeish}")
+ command("git log -n 30 #{treeish}")
end
def blame(path)
Stage this hunk [y,n,a,d,/,j,J,g,e,?]?
À cette étape, vous disposez de bon nombre d’options. ? vous liste les
actions possibles dont voici une traduction :
Indexer cette partie [y,n,a,d,/,j,J,g,e,?]? ?
y - indexer cette partie
n - ne pas indexer cette partie
a - indexer cette partie et toutes celles restantes dans ce fichier
d - ne pas indexer cette partie ni aucune de celles restantes dans ce fichier
g - sélectionner une partie à voir
/ - chercher une partie correspondant à la regexp donnée
j - laisser cette partie non décidée, voir la prochaine partie non encore décidée
J - laisser cette partie non décidée, voir la prochaine partie
k - laisser cette partie non décidée, voir la partie non encore décidée précédente
K - laisser cette partie non décidée, voir la partie précédente
s - couper la partie courante en parties plus petites
e - modifier manuellement la partie courante
? - afficher l'aide
En règle générale, vous choisirez y ou n pour indexer ou non chacun
des blocs, mais tout indexer pour certains fichiers ou remettre à plus
tard le choix pour un bloc peut également être utile. Si vous indexez
une partie d’un fichier et une autre non, votre statut ressemblera à peu
près à ceci :
What now> 1
staged unstaged path
1: unchanged +0/-1 TODO
2: +1/-1 nothing index.html
3: +1/-1 +4/-0 lib/simplegit.rb
Le statut pour le fichier simplegit.rb est intéressant. Il vous montre
que quelques lignes sont indexées et d’autres non. Vous avez
partiellement indexé ce fichier. Dès lors, vous pouvez quitter l’ajout
interactif et exécuter git commit pour valider les fichiers
partiellement indexés.
Enfin, vous pouvez vous passer du mode interactif pour indexer
partiellement un fichier ; vous pouvez faire de même avec git add -p
ou git add --patch en ligne de commande.
De plus, vous pouvez utiliser le mode patch pour réinitialiser
partiellement des fichiers avec la commande reset --patch, pour
extraire des parties de fichiers avec checkout --patch et pour remiser
des parties de fichiers avec stash save --patch. Nous explorerons plus
en détail chacune des ces commandes quand nous aborderons les usages
avancés de ces commandes.
Remisage et nettoyage
Souvent, lorsque vous avez travaillé sur une partie de votre projet, les
choses sont dans un état instable mais vous voulez changer de branche
pour travailler momentanément sur autre chose. Le problème est que vous
ne voulez pas valider un travail à moitié fait seulement pour pouvoir y
revenir plus tard. La réponse à cette problématique est la commande
git stash.
Remiser prend l’état en cours de votre répertoire de travail, c’est-à-dire les fichiers modifiés et l’index, et l’enregistre dans la pile des modifications non finies que vous pouvez ré-appliquer à n’importe quel moment.
Remiser votre travail
Pour démontrer cette possibilité, allez dans votre projet et commencez à
travailler sur quelques fichiers et indexez l’un de ces changements. Si
vous exécutez git status, vous pouvez voir votre état modifié :
$ git status
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
modifié : index.html
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : lib/simplegit.rb
À ce moment-là, vous voulez changer de branche, mais vous ne voulez pas
encore valider ce travail ; vous allez donc remiser vos modifications.
Pour créer une nouvelle remise sur votre pile, exécutez git stash :
$ git stash
Saved working directory and index state \
"WIP on master: 049d078 added the index file"
HEAD is now at 049d078 added the index file
(To restore them type "git stash apply")
Votre répertoire de travail est propre :
$ git status
Sur la branche master
rien à valider, la copie de travail est propre
À ce moment, vous pouvez facilement changer de branche et travailler
autre part ; vos modifications sont conservées dans votre pile. Pour
voir quelles remises vous avez sauvegardées, vous pouvez utiliser la
commande git stash list :
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051... Revert "added file_size"
stash@{2}: WIP on master: 21d80a5... added number to log
Dans ce cas, deux remises ont été créées précédemment, vous avez donc
accès à trois travaux remisés différents. Vous pouvez ré-appliquer celui
que vous venez juste de remiser en utilisant la commande affichée dans
la sortie d’aide de la première commande de remise : git stash apply.
Si vous voulez appliquer une remise plus ancienne, vous pouvez la
spécifier en la nommant, comme ceci : git stash apply stash@{2}. Si
vous ne spécifiez pas une remise, Git présume que vous voulez la remise
la plus récente et essaye de l’appliquer.
$ git stash apply
Sur la branche master
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modified: index.html
modified: lib/simplegit.rb
Vous pouvez observer que Git remodifie les fichiers non validés lorsque vous avez créé la remise. Dans ce cas, vous aviez un répertoire de travail propre lorsque vous avez essayé d’appliquer la remise et vous l’avez fait sur la même branche que celle où vous l’aviez créée ; mais avoir un répertoire de travail propre et l’appliquer sur la même branche n’est pas nécessaire pour réussir à appliquer une remise. Vous pouvez très bien créer une remise sur une branche, changer de branche et essayer d’appliquer ces modifications. Vous pouvez même avoir des fichiers modifiés et non validés dans votre répertoire de travail quand vous appliquez une remise, Git vous indique les conflits de fusions si quoi que ce soit ne s’applique pas proprement.
Par défaut, les modifications de vos fichiers sont ré-appliquées, mais
pas les indexations. Pour cela, vous devez exécuter la commande
git stash apply avec l’option --index pour demander à Git d’essayer
de ré-appliquer les modifications de votre index. Si vous exécutez cela
à la place de la commande précédente, vous vous retrouvez dans la
position d’origine précédent la remise :
$ git stash apply --index
Sur la branche master
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
modifié : index.html
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modified: lib/simplegit.rb
L’option apply essaye seulement d’appliquer le travail remisé, vous
aurez toujours la remise dans votre pile. Pour la supprimer, vous pouvez
exécuter git stash drop avec le nom de la remise à supprimer :
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051... Revert "added file_size"
stash@{2}: WIP on master: 21d80a5... added number to log
$ git stash drop stash@{0}
Dropped stash@{0} (364e91f3f268f0900bc3ee613f9f733e82aaed43)
Vous pouvez également exécuter git stash pop pour appliquer et
supprimer immédiatement la remise de votre pile.
Remisage créatif
Il existe des variantes de remisages qui peuvent s’avérer utiles. La
première option assez populaire est l’option --keep-index de la
commande stash save. Elle indique à Git de ne pas remiser ce qui
aurait été déjà indexé au moyen de la commande git add.
C’est particulièrement utile si vous avez réalisé des modifications mais souhaitez ne valider que certaines d’entre elles et gérer le reste plus tard.
$ git status -s
M index.html
M lib/simplegit.rb
$ git stash --keep-index
Saved working directory and index state WIP on master: 1b65b17 added the index file
HEAD is now at 1b65b17 added the index file
$ git status -s
M index.html
Une autre option utile de stash est la possibilité de remiser les
fichiers non suivis aussi bien que les fichiers suivis. Par défaut,
git stash ne sauve que les fichiers qui sont déjà suivis ou indexés.
Si vous spécifiez l’option --include-untracked ou -u, Git remisera
aussi les fichiers non-suivis du répertoire de travail.
$ git status -s
M index.html
M lib/simplegit.rb
?? new-file.txt
$ git stash -u
Saved working directory and index state WIP on master: 1b65b17 added the index file
HEAD is now at 1b65b17 added the index file
$ git status -s
$
Enfin, si vous ajoutez l’option --patch, Git ne remisera pas tout le
contenu modifié, mais vous invitera à sélectionner interactivement les
modifications que vous souhaitez remiser et celles que vous souhaiter
conserver dans la copie de travail.
$ git stash --patch
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 66d332e..8bb5674 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -16,6 +16,10 @@ class SimpleGit
return `#{git_cmd} 2>&1`.chomp
end
end
+
+ def show(treeish = 'master')
+ command("git show #{treeish}")
+ end
end
test
Stash this hunk [y,n,q,a,d,/,e,?]? y
Saved working directory and index state WIP on master: 1b65b17 added the index file
Défaire l’effet d’une remise
Dans certains cas, il est souhaitable de pouvoir appliquer une
modification remisée, réaliser d’autres modifications, puis défaire les
modifications de la remise. Git ne fournit pas de commande
stash unapply mais il est possible d’obtenir le même effet en
extrayant les modifications qui constituent la remise et en appliquant
leur inverse :
$ git stash show -p stash@{0} | git apply -R
Ici aussi, si la remise n’est pas indiquée, Git utilise la plus récente.
$ git stash show -p | git apply -R
La création d’un alias permettra d’ajouter effectivement la commande
stash-unapply à votre Git. Par exemple :
$ git config --global alias.stash-unapply '!git stash show -p | git apply -R'
$ git stash
$ #... travail, travail, travail
$ git stash-unapply
Créer une branche depuis une remise
Si vous remisez votre travail, et l’oubliez pendant un temps en
continuant sur la branche où vous avez créé la remise, vous pouvez avoir
un problème en ré-appliquant le travail. Si l’application de la remise
essaye de modifier un fichier que vous avez modifié depuis, vous allez
obtenir des conflits de fusion et vous devrez essayer de les résoudre.
Si vous voulez un moyen plus facile de tester une nouvelle fois les
modifications remisées, vous pouvez exécuter git stash branch qui
créera une nouvelle branche à votre place, récupérant le commit où
vous étiez lorsque vous avez créé la remise, ré-appliquera votre travail
dedans, et supprimera finalement votre remise si cela a réussi :
$ git stash branch testchanges
Basculement sur la nouvelle branche 'testchanges'
Sur la branche testchanges
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
modifié : index.html
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modified: lib/simplegit.rb
refs/stash@{0} supprimé (f0dfc4d5dc332d1cee34a634182e168c4efc3359)
C’est un bon raccourci pour récupérer facilement du travail remisé et pouvoir travailler dessus dans une nouvelle branche.
Nettoyer son répertoire de travail
Enfin, vous pouvez souhaiter ne pas remiser certains fichiers de votre
répertoire de travail, mais simplement vous en débarrasser. La commande
git clean s’en chargera pour vous.
Le besoin le plus commun pourra être d’éliminer les scories générées par les fusions ou les outils externes ou d’éliminer les artefacts de compilation pour pouvoir relancer une compilation propre.
Faites néanmoins très attention avec cette commande car elle supprime
des fichiers non-suivis de votre répertoire de travail. Si vous changez
d’avis, il est souvent impossible de récupérer après coup le contenu de
ces fichiers. Une option plus sécurisée consiste à lancer
git stash --all pour tout sauvegarder dans une remise.
En supposant que vous souhaitez réellement éliminer les scories et
nettoyer votre répertoire de travail, vous pouvez lancer git clean.
Pour supprimer tous les fichiers non-suivis, vous pouvez lancer
git clean -f -d, qui effacera aussi tout sous-répertoire vide.
L’option -f signifie « force », soit « fais-le réellement ».
Si vous souhaitez visualiser ce qui serait fait, vous pouvez lancer la
commande avec l’option -n qui signifie « fais-le à blanc et montre-moi
ce qui serait supprimé ».
$ git clean -d -n
Supprimerait test.o
Supprimerait tmp/
Par défaut, la commande git clean ne va supprimer que les fichiers
non-suivis qui ne sont pas ignorés. Tout fichier qui correspond à un
motif de votre fichier .gitignore ou tout autre fichier similaire ne
sera pas supprimé. Si vous souhaitez supprimer aussi ces fichiers, comme
par exemple les fichiers .o généré par un compilateur pour faire une
compilation totale, vous pouvez ajouter l’option -x à la commande de
nettoyage.
$ git status -s
M lib/simplegit.rb
?? build.TMP
?? tmp/
$ git clean -n -d
Supprimerait build.TMP
Supprimerait tmp/
$ git clean -n -d -x
Supprimerait build.TMP
Supprimerait test.o
Supprimerait tmp/
Si vous ne savez pas ce que la commande git clean va effectivement
supprimer, lancez-la une première fois avec -n par sécurité avant de
transformer le -n en -f et nettoyer définitivement. Un autre choix
pour s’assurer de ce qui va être effacé consiste à lancer la commande
avec l’option -i ou --interactive.
La commande sera lancée en mode interactif.
$ git clean -x -i
Supprimerait les éléments suivants :
build.TMP test.o
*** Commandes ***
1: clean 2: filter by pattern 3: select by numbers 4: ask each 5: quit
6: help
Et maintenant ?>
De cette manière, vous pouvez détailler chaque fichier individuellement ou spécifier un motif pour la suppression interactive.
Signer votre travail
Git est cryptographiquement sûr, mais il n’est pas infaillible. Si vous récupérez le travail d’autres personnes sur Internet et souhaitez vérifier que les commits ont effectivement une source de confiance, Git propose quelques méthodes pour signer et vérifier ceci au moyen de GPG.
Introduction à GPG
Avant tout, si vous voulez pouvoir signer quoique ce soit, vous devez avoir un GPG configuré et une clé personnelle.
$ gpg --list-keys
/Users/schacon/.gnupg/pubring.gpg
---------------------------------
pub 2048R/0A46826A 2014-06-04
uid Scott Chacon (Git signing key) <schacon@gmail.com>
sub 2048R/874529A9 2014-06-04
Si vous n’avez pas de clé, vous pouvez en générer une avec la commande
gpg --gen-key.
gpg --gen-key
A présent que vous avez une clé privée permettant de signer, vous pouvez
configurer Git pour l’utiliser pour signer diverses choses en
renseignant le paramètre de configuration user.signingkey.
git config --global user.signingkey 0A46826A
A partir de maintenant, Git utilisera par défaut votre clé pour signer les étiquettes et les commits que vous souhaitez.
Signer des étiquettes
Avec votre clé privée GPG renseignée, vous pouvez signer des étiquettes.
Tout ce que vous avez à faire, c’est remplacer -a par -s :
$ git tag -s v1.5 -m 'mon étiquette signée 1.5'
You need a passphrase to unlock the secret key for
user: "Ben Straub <ben@straub.cc>"
2048-bit RSA key, ID 800430EB, created 2014-05-04
Si vous lancez git show sur cette étiquette, vous pouvez voir votre
signature GPG attachée :
$ git show v1.5
tag v1.5
Tagger: Ben Straub <ben@straub.cc>
Date: Sat May 3 20:29:41 2014 -0700
mon étiquette signée 1.5
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABAgAGBQJTZbQlAAoJEF0+sviABDDrZbQH/09PfE51KPVPlanr6q1v4/Ut
LQxfojUWiLQdg2ESJItkcuweYg+kc3HCyFejeDIBw9dpXt00rY26p05qrpnG+85b
hM1/PswpPLuBSr+oCIDj5GMC2r2iEKsfv2fJbNW8iWAXVLoWZRF8B0MfqX/YTMbm
ecorc4iXzQu7tupRihslbNkfvfciMnSDeSvzCpWAHl7h8Wj6hhqePmLm9lAYqnKp
8S5B/1SSQuEAjRZgI4IexpZoeKGVDptPHxLLS38fozsyi0QyDyzEgJxcJQVMXxVi
RUysgqjcpT8+iQM1PblGfHR4XAhuOqN5Fx06PSaFZhqvWFezJ28/CLyX5q+oIVk=
EFTF
-----END PGP SIGNATURE-----
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar 17 21:52:11 2008 -0700
changed the version number
Verifier des étiquettes
Pour vérifier une étiquette signée, vous utilisez
git tag -v [nom-de-l-etiquette]. Cette commande utilise GPG pour
vérifier la signature. Vous devez posséder la clé publique du signataire
dans votre trousseau pour que cela fonctionne.
$ git tag -v v1.4.2.1
object 883653babd8ee7ea23e6a5c392bb739348b1eb61
type commit
tag v1.4.2.1
tagger Junio C Hamano <junkio@cox.net> 1158138501 -0700
GIT 1.4.2.1
Minor fixes since 1.4.2, including git-mv and git-http with alternates.
gpg: Signature made Wed Sep 13 02:08:25 2006 PDT using DSA key ID F3119B9A
gpg: Good signature from "Junio C Hamano <junkio@cox.net>"
gpg: aka "[jpeg image of size 1513]"
Primary key fingerprint: 3565 2A26 2040 E066 C9A7 4A7D C0C6 D9A4 F311 9B9A
Si vous ne possédez pas la clé publique du signataire, vous obtiendrez plutôt quelque chose comme :
gpg: Signature made Wed Sep 13 02:08:25 2006 PDT using DSA key ID F3119B9A
gpg: Can't check signature: public key not found
error: could not verify the tag 'v1.4.2.1'
Signer des commits
Dans les versions les plus récentes de Git (à partir de v1.7.9), vous
pouvez maintenant signer aussi les commits individuels. Si signer
directement des commits au lieu d’étiquettes vous intéresse, tout ce
que vous avez à faire est d’ajouter l’option -S à votre commande
git commit.
$ git commit -a -S -m 'commit signé'
You need a passphrase to unlock the secret key for
user: "Scott Chacon (Git signing key) <schacon@gmail.com>"
2048-bit RSA key, ID 0A46826A, created 2014-06-04
[master 5c3386c] commit signé
4 files changed, 4 insertions(+), 24 deletions(-)
rewrite Rakefile (100%)
create mode 100644 lib/git.rb
Pour visualiser et vérifier ces signatures, il y a l’option
--show-signature pour git log.
$ git log --show-signature -1
commit 5c3386cf54bba0a33a32da706aa52bc0155503c2
gpg: Signature made Wed Jun 4 19:49:17 2014 PDT using RSA key ID 0A46826A
gpg: Good signature from "Scott Chacon (Git signing key) <schacon@gmail.com>"
Author: Scott Chacon <schacon@gmail.com>
Date: Wed Jun 4 19:49:17 2014 -0700
commit signé
En complément, vous pouvez configurer git log pour vérifier toutes les
signatures qu’il trouvera et les montrer grâce au formatage %G?.
$ git log --pretty="format:%h %G? %aN %s"
5c3386c G Scott Chacon commit signé
ca82a6d N Scott Chacon changed the verison number
085bb3b N Scott Chacon removed unnecessary test code
a11bef0 N Scott Chacon first commit
Ici nous pouvons voir que seul le dernier commit est signé et valide tandis que les précédents ne le sont pas.
Depuis Git 1.8.3, git merge et git pull peuvent vérifier et annuler
une fusion d’un commit qui ne porte pas de signature GPG de confiance,
avec la commande --verify-signatures.
Si vous utilisez cette option lors de la fusion d’une branche et qu’elle contient des commits qui ne sont pas signés et valides, la fusion échouera.
$ git merge --verify-signatures non-verify
fatal: La validation ab06180 n'a pas de signature GPG.
Si la fusion ne contient que des commits signés valides, la commande de fusion vous montrera toutes les signatures vérifiées et démarrera la fusion proprement dite.
$ git merge --verify-signatures signed-branch
La validation 13ad65e a une signature GPG correcte par Scott Chacon (Git signing key) <schacon@gmail.com>
Mise à jour 5c3386c..13ad65e
Avance rapide
README | 2 ++
1 file changed, 2 insertions(+)
Vous pouvez aussi utiliser l’option -S avec la commande git merge
elle-même pour signer le commit de fusion. L’exemple suivant vérifie
que tous les commits dans la branche à fusionner sont signés et de
plus signe le commit de fusion résultant.
$ git merge --verify-signatures -S signed-branch
Commit 13ad65e a une signature GPG correcte par Scott Chacon (Git signing key) <schacon@gmail.com>
You need a passphrase to unlock the secret key for
user: "Scott Chacon (Git signing key) <schacon@gmail.com>"
2048-bit RSA key, ID 0A46826A, created 2014-06-04
Merge made by the 'recursive' strategy.
README | 2 ++
1 file changed, 2 insertions(+)
Tout le monde doit signer
Signer les étiquettes et les commits, c’est bien mais si vous décidez d’utiliser cette fonction dans votre méthode de travail, il faudra s’assurer que tous les membres de votre équipe comprennent comment s’y prendre. Sinon, vous allez devoir passer du temps à aider les personnes à réécrire leurs commits en version signée. Assurez-vous de bien comprendre GPG et les bénéfices de la signature avant d’adopter cette pratique dans vos méthodes de travail.
Recherche
Quelle que soit la taille de votre code, vous avez souvent besoin de chercher où une fonction est appelée ou définie, ou de retrouver l’historique d’une méthode. Git fournit quelques outils permettant rapidement de rechercher dans le code et les commits stockés dans votre base de données. Nous allons en détailler quelques uns.
Git grep
Git est livré avec une commande appelée grep qui permet de rechercher
facilement une chaîne de caractères ou une expression régulière dans une
arborescence validée ou dans le répertoire de travail. Pour tous les
exemples qui suivent, nous allons utiliser le dépôt de Git lui-même.
Par défaut, git grep recherche dans le répertoire de travail. Vous
pouvez passer l’option -n pour afficher les numéros des lignes des
correspondances.
$ git grep -n gmtime_r
compat/gmtime.c:3:#undef gmtime_r
compat/gmtime.c:8: return git_gmtime_r(timep, &result);
compat/gmtime.c:11:struct tm *git_gmtime_r(const time_t *timep, struct tm *result)
compat/gmtime.c:16: ret = gmtime_r(timep, result);
compat/mingw.c:606:struct tm *gmtime_r(const time_t *timep, struct tm *result)
compat/mingw.h:162:struct tm *gmtime_r(const time_t *timep, struct tm *result);
date.c:429: if (gmtime_r(&now, &now_tm))
date.c:492: if (gmtime_r(&time, tm)) {
git-compat-util.h:721:struct tm *git_gmtime_r(const time_t *, struct tm *);
git-compat-util.h:723:#define gmtime_r git_gmtime_r
La commande grep peut être enrichie grâce à un certain nombre
d’options intéressantes.
Par exemple, pour l’appel précédent, vous pouvez indiquer à Git de
résumer le résultat en ne montrant que les fichiers et le nombre de
correspondances au moyen de l’option --count :
$ git grep --count gmtime_r
compat/gmtime.c:4
compat/mingw.c:1
compat/mingw.h:1
date.c:2
git-compat-util.h:2
Si vous souhaitez voir dans quelle méthode ou fonction la correspondance
a été trouvée, vous pouvez passer l’option -p :
$ git grep -p gmtime_r *.c
date.c=static int match_multi_number(unsigned long num, char c, const char *date, char *end, struct tm *tm)
date.c: if (gmtime_r(&now, &now_tm))
date.c=static int match_digit(const char *date, struct tm *tm, int *offset, int *tm_gmt)
date.c: if (gmtime_r(&time, tm)) {
Ici, on peut voir que gmtime_r est appelée dans les fonctions
match_multi_number et match_digit du fichier date.c.
Vous pouvez aussi rechercher des combinaisons plus complexes de chaînes
de caractères avec l’option --and qui force plusieurs correspondances
sur la même ligne. Par exemple, recherchons toutes les lignes qui
définissent une constante qui contient au choix « LINK » ou « BUF_MAX »
dans la base de code de Git avant la version 1.8.0.
Ici, nous allons utiliser les options --break et --heading qui
aident à découper le résultat dans un format plus digeste.
$ git grep --break --heading \
-n -e '#define' --and \( -e LINK -e BUF_MAX \) v1.8.0
v1.8.0:builtin/index-pack.c
62:#define FLAG_LINK (1u<<20)
v1.8.0:cache.h
73:#define S_IFGITLINK 0160000
74:#define S_ISGITLINK(m) (((m) & S_IFMT) == S_IFGITLINK)
v1.8.0:environment.c
54:#define OBJECT_CREATION_MODE OBJECT_CREATION_USES_HARDLINKS
v1.8.0:strbuf.c
326:#define STRBUF_MAXLINK (2*PATH_MAX)
v1.8.0:symlinks.c
53:#define FL_SYMLINK (1 << 2)
v1.8.0:zlib.c
30:/* #define ZLIB_BUF_MAX ((uInt)-1) */
31:#define ZLIB_BUF_MAX ((uInt) 1024 * 1024 * 1024) /* 1GB */
La commande git grep a quelques avantages sur les commandes de
recherche normales telles que grep et ack. Le premier est qu’elle
est vraiment rapide, le second est qu’elle vous permet de rechercher
dans n’importe quelle arborescence Git, pas seulement la copie de
travail. Comme nous l’avons vu dans l’exemple ci-dessus, nous avons
cherché des termes dans une version ancienne du code source de Git, pas
dans la dernière version extraite.
Recherche dans le journal Git
Peut-être ne cherchez-vous pas où un terme apparaît, mais plutôt
quand il existait ou fut introduit. La commande git log comprend
un certain nombre d’outils puissants pour trouver des commits
spécifiques par le contenu de leurs messages ou le contenu des diffs
qu’ils introduisent.
Si vous voulez trouver par exemple quand la constante ZLIB_BUF_MAX a
été initialement introduite, nous pouvons indiquez à Git de ne montrer
que les commits qui soit ajoutent soit retirent la chaîne avec
l’option -S.
$ git log -SZLIB_BUF_MAX --oneline
e01503b zlib: allow feeding more than 4GB in one go
ef49a7a zlib: zlib can only process 4GB at a time
Si nous regardons la diff de ces commits, nous pouvons voir que dans
ef49a7a, la constante a été introduite et qu’elle a été modifiée dans
e01503b.
Si vous devez être plus spécifique, vous pouvez fournir une expression
régulière à rechercher avec l’option -G.
Recherche des évolutions d’une ligne
Un autre outil avancé de recherche dans l’historique qui peut s’avérer
très utile est la recherche de l’historique d’une ligne. C’est une
addition assez récente et peu connue, mais elle peut être très efficace.
On l’active avec l’option -L de git log et elle vous montre
l’historique d’une fonction ou d’une ligne dans votre base de code.
Par exemple, si nous souhaitions voir toutes les modifications réalisées
sur la fonction git_deflate_bound dans le fichier zlib.c, nous
pourrions lancer git log -L :git_deflate_bound:zlib.c. Cette commande
va essayer de déterminer les limites de cette fonction et de rechercher
dans l’historique chaque modification réalisée sur la fonction comme une
série de patchs jusqu’au moment de sa création.
$ git log -L :git_deflate_bound:zlib.c
commit ef49a7a0126d64359c974b4b3b71d7ad42ee3bca
Author: Junio C Hamano <gitster@pobox.com>
Date: Fri Jun 10 11:52:15 2011 -0700
zlib: zlib can only process 4GB at a time
diff --git a/zlib.c b/zlib.c
--- a/zlib.c
+++ b/zlib.c
@@ -85,5 +130,5 @@
-unsigned long git_deflate_bound(z_streamp strm, unsigned long size)
+unsigned long git_deflate_bound(git_zstream *strm, unsigned long size)
{
- return deflateBound(strm, size);
+ return deflateBound(&strm->z, size);
}
commit 225a6f1068f71723a910e8565db4e252b3ca21fa
Author: Junio C Hamano <gitster@pobox.com>
Date: Fri Jun 10 11:18:17 2011 -0700
zlib: wrap deflateBound() too
diff --git a/zlib.c b/zlib.c
--- a/zlib.c
+++ b/zlib.c
@@ -81,0 +85,5 @@
+unsigned long git_deflate_bound(z_streamp strm, unsigned long size)
+{
+ return deflateBound(strm, size);
+}
+
Si Git ne peut pas déterminer comment trouver la fonction ou la méthode
dans votre langage de programmation, vous pouvez aussi fournir une
regex. Par exemple, cela aurait donné le même résultat avec
git log -L '/unsigned long git_deflate_bound/',/^}/:zlib.c. Vous
auriez pu aussi spécifier un intervalle de lignes ou un numéro de ligne
et vous auriez obtenu le même type de résultat.
Réécrire l’historique
Bien souvent, lorsque vous travaillez avec Git, vous souhaitez modifier votre historique de validation pour une raison quelconque. Une des choses merveilleuses de Git est qu’il vous permet de prendre des décisions le plus tard possible. Vous pouvez décider quels fichiers vont dans quel commit avant que vous ne validiez l’index, vous pouvez décider que vous ne voulez pas encore montrer que vous travaillez sur quelque chose avec les remises, et vous pouvez réécrire les commits déjà sauvegardés pour qu’ils ressemblent à quelque chose d’autre. Cela peut signifier changer l’ordre des commits, modifier les messages ou modifier les fichiers appartenant au commit, rassembler ou scinder des commits, ou supprimer complètement des commits ; tout ceci avant de les partager avec les autres.
Dans cette section, nous expliquerons comment accomplir ces tâches très utiles pour que vous puissiez remodeler votre historique de validation comme vous le souhaitez avant de le partager avec autrui.
Modifier la dernière validation
Modifier votre dernière validation est probablement la réécriture de l’historique que vous allez utiliser le plus souvent. Vous voudrez souvent faire deux choses basiques à votre dernier commit : modifier le message de validation ou changer le contenu que vous avez enregistré en ajoutant, modifiant ou supprimant des fichiers.
Si vous voulez seulement modifier votre dernier message de validation, c’est vraiment simple :
$ git commit --amend
Cela ouvre votre éditeur de texte contenant votre dernier message, prêt à être modifié. Lorsque vous sauvegardez et fermez l’éditeur, Git enregistre la nouvelle validation contenant le message et en fait votre dernier commit.
Si vous voulez modifier le contenu de votre validation en ajoutant ou
modifiant des fichiers, sûrement parce que vous avez oublié d’ajouter
les fichiers nouvellement créés quand vous avez validé la première fois,
la procédure fonctionne grosso-modo de la même manière. Vous indexez les
modifications que vous voulez en exécutant git add ou git rm, et le
prochain git commit --amend prendra votre index courant et en fera le
contenu de votre nouvelle validation.
Vous devez être prudent avec cette technique car votre modification
modifie également le SHA-1 du commit. Cela ressemble à un tout petit
rebase. Ne modifiez pas votre dernière validation si vous l’avez déjà
publiée !
Modifier plusieurs messages de validation
Pour modifier une validation qui est plus loin dans votre historique,
vous devez utiliser des outils plus complexes. Git ne contient pas
d’outil de modification d’historique, mais vous pouvez utiliser l’outil
rebase pour rebaser une suite de commits depuis la branche HEAD
plutôt que de les déplacer vers une autre branche. Avec l’outil rebase
interactif, vous pouvez vous arrêter après chaque commit que vous
voulez modifier et changer le message, ajouter des fichiers ou quoi que
ce soit que vous voulez. Vous pouvez exécuter rebase interactivement
en ajoutant l’option -i à git rebase. Vous devez indiquer jusqu’à
quand remonter dans votre historique en donnant à la commande le
commit sur lequel vous voulez vous rebaser.
Par exemple, si vous voulez modifier les 3 derniers messages de
validation ou n’importe lequel des messages dans ce groupe, vous
fournissez à git rebase -i le parent du dernier commit que vous
voulez éditer, qui est HEAD~2^ or HEAD~3. Il peut être plus facile
de se souvenir de ~3, car vous essayez de modifier les 3 derniers
commits, mais gardez à l’esprit que vous désignez le 4e, le parent du
dernier commit que vous voulez modifier :
$ git rebase -i HEAD~3
Souvenez-vous également que ceci est une commande de rebasage, chaque
commit inclus dans l’intervalle HEAD~3..HEAD sera réécrit, que vous
changiez le message ou non. N’incluez pas, dans cette commande, de
commit que vous avez déjà poussé sur un serveur central. Le faire
entraînera la confusion chez les autres développeurs en leur fournissant
une version altérée des mêmes modifications.
Exécuter cette commande vous donne la liste des validations dans votre éditeur de texte, ce qui ressemble à :
pick f7f3f6d changed my name a bit
pick 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
# Rebase 710f0f8..a5f4a0d onto 710f0f8
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
Il est important de signaler que les commits sont listés dans l’ordre
inverse de celui que vous voyez normalement en utilisant la commande
log. Si vous exécutez la commande log, vous verrez quelque chose de
ce genre :
$ git log --pretty=format:"%h %s" HEAD~3..HEAD
a5f4a0d added cat-file
310154e updated README formatting and added blame
f7f3f6d changed my name a bit
Remarquez l’ordre inverse. Le rebasage interactif va créer un script à
exécuter. Il commencera au commit que vous spécifiez sur la ligne de
commande (HEAD~3) et refera les modifications introduites dans chacun
des commits du début à la fin. Il ordonne donc le plus vieux au début,
plutôt que le plus récent, car c’est celui qu’il refera en premier.
Vous devez éditer le script afin qu’il s’arrête au commit que vous voulez modifier. Pour cela, remplacer le mot « pick » par le mot « edit » pour chaque commit après lequel vous voulez que le script s’arrête. Par exemple, pour modifier uniquement le message du troisième commit, vous modifiez le fichier pour ressembler à :
edit f7f3f6d changed my name a bit
pick 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
Au moment où vous sauvegardez et quittez l’éditeur, Git revient au dernier commit de cette liste et vous laisse sur une ligne de commande avec le message suivant :
$ git rebase -i HEAD~3
Stopped at 7482e0d... updated the gemspec to hopefully work better
You can amend the commit now, with
git commit --amend
Once you’re satisfied with your changes, run
git rebase --continue
Ces instructions vous disent exactement quoi faire. Entrez :
$ git commit --amend
Modifiez le message de commit et quittez l’éditeur. Puis exécutez :
$ git rebase --continue
Cette commande appliquera les deux autres commits automatiquement. Si vous remplacez « pick » en « edit » sur plusieurs lignes, vous pouvez répéter ces étapes pour chaque commit que vous avez marqué pour modification. Chaque fois, Git s’arrêtera, vous laissant modifier le commit et continuera lorsque vous aurez fini.
Réordonner les commits
Vous pouvez également utiliser les rebasages interactifs afin de réordonner ou supprimer entièrement des commits. Si vous voulez supprimer le commit « added cat-file » et modifier l’ordre dans lequel les deux autres commits se trouvent dans l’historique, vous pouvez modifier le script de rebasage :
pick f7f3f6d changed my name a bit
pick 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
afin qu’il ressemble à ceci :
pick 310154e updated README formatting and added blame
pick f7f3f6d changed my name a bit
Lorsque vous sauvegardez et quittez l’éditeur, Git remet votre branche
au niveau du parent de ces commits, applique 310154e puis f7f3f6d
et s’arrête. Vous venez de modifier l’ordre de ces commits et de
supprimer entièrement le commit « added cat-file ».
Écraser un commit
Il est également possible de prendre une série de commits et de les rassembler en un seul avec l’outil de rebasage interactif. Le script affiche des instructions utiles dans le message de rebasage :
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
Si, à la place de « pick » ou « edit », vous spécifiez « squash », Git applique cette modification et la modification juste précédente et fusionne les messages de validation. Donc, si vous voulez faire un seul commit de ces trois validations, vous faites en sorte que le script ressemble à ceci :
pick f7f3f6d changed my name a bit
squash 310154e updated README formatting and added blame
squash a5f4a0d added cat-file
Lorsque vous sauvegardez et quittez l’éditeur, Git applique ces trois modifications et vous remontre l’éditeur contenant maintenant la fusion des 3 messages de validation :
# This is a combination of 3 commits.
# The first commit's message is:
changed my name a bit
# This is the 2nd commit message:
updated README formatting and added blame
# This is the 3rd commit message:
added cat-file
Lorsque vous sauvegardez cela, vous obtenez un seul commit amenant les modifications des trois commits précédents.
Diviser un commit
Pour diviser un commit, il doit être défait, puis partiellement indexé
et validé autant de fois que vous voulez pour en finir avec lui. Par
exemple, supposons que vous voulez diviser le commit du milieu dans
l’exemple des trois commits précédents. Plutôt que « updated README
formatting and added blame », vous voulez le diviser en deux
commits : « updated README formatting » pour le premier, et « added
blame » pour le deuxième. Vous pouvez le faire avec le script
rebase -i en remplaçant l’instruction sur le commit que vous voulez
diviser en « edit » :
pick f7f3f6d changed my name a bit
edit 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
Puis, lorsque le script vous laisse accès à la ligne de commande, vous
pouvez annuler (reset) ce commit et revalider les modifications
que vous voulez pour créer plusieurs commits. En reprenant l’exemple,
lorsque vous sauvegardez et quittez l’éditeur, Git revient au parent de
votre premier commit de votre liste, applique le premier commit
(f7f3f6d), applique le deuxième (310154e), et vous laisse accès à la
console. Là, vous pouvez faire une réinitialisation mélangée (mixed
reset) de ce commit avec git reset HEAD^, qui défait ce commit
et laisse les fichiers modifiés non indexés. Maintenant, vous pouvez
indexer et valider les fichiers sur plusieurs validations, et exécuter
git rebase --continue quand vous avez fini :
$ git reset HEAD^
$ git add README
$ git commit -m 'updated README formatting'
$ git add lib/simplegit.rb
$ git commit -m 'added blame'
$ git rebase --continue
Git applique le dernier commit (a5f4a0d) de votre script, et votre
historique ressemblera alors à :
$ git log -4 --pretty=format:"%h %s"
1c002dd added cat-file
9b29157 added blame
35cfb2b updated README formatting
f3cc40e changed my name a bit
Une fois encore, ceci modifie les empreintes SHA-1 de tous les commits dans votre liste, soyez donc sûr qu’aucun commit de cette liste n’ait été poussé dans un dépôt partagé.
L’option nucléaire : filter-branch
Il existe une autre option de la réécriture d’historique que vous pouvez
utiliser si vous avez besoin de réécrire un grand nombre de commits
d’une manière scriptable ; par exemple, modifier globalement votre
adresse mail ou supprimer un fichier de tous les commits. La commande
est filter-branch, et elle peut réécrire des pans entiers de votre
historique, vous ne devriez donc pas l’utiliser à moins que votre projet
ne soit pas encore public ou que personne n’ait encore travaillé sur les
commits que vous allez réécrire. Cependant, cela peut être très utile.
Vous allez maintenant apprendre quelques usages communs pour vous donner
une idée de ses capacités.
Supprimer un fichier de chaque commit
Cela arrive assez fréquemment. Quelqu’un a accidentellement validé un
énorme fichier binaire avec une commande git add . irréfléchie, et
vous voulez le supprimer partout. Vous avez peut-être validé un fichier
contenant un mot de passe et vous voulez rendre votre projet open
source. filter-branch est l’outil que vous voulez probablement
utiliser pour nettoyer votre historique entier. Pour supprimer un
fichier nommé « passwords.txt » de tout votre historique, vous pouvez
utiliser l’option --tree-filter de filter-branch :
$ git filter-branch --tree-filter 'rm -f passwords.txt' HEAD
Rewrite 6b9b3cf04e7c5686a9cb838c3f36a8cb6a0fc2bd (21/21)
Ref 'refs/heads/master' was rewritten
L’option --tree-filter exécute la commande spécifiée pour chaque
commit et le revalide ensuite. Dans le cas présent, vous supprimez le
fichier nommé « passwords.txt » de chaque contenu, qu’il existait ou
non. Si vous voulez supprimer tous les fichiers temporaires des éditeurs
validés accidentellement, vous pouvez exécuter une commande telle que
git filter-branch --tree-filter "find * -type f -name '*~' -delete" HEAD.
Vous pourrez alors regarder Git réécrire l’arbre des commits et
revalider à chaque fois, pour finir en modifiant la référence de la
branche. C’est généralement une bonne idée de le faire dans un branche
de test puis de faire une réinitialisation forte (hard-reset) de
votre branche master si le résultat vous convient. Pour exécuter
filter-branch sur toutes vos branches, vous pouvez ajouter --all à
la commande.
Faire d’un sous-répertoire la nouvelle racine
Supposons que vous avez importé votre projet depuis un autre système de
gestion de configuration et que vous avez des sous-répertoires qui n’ont
aucun sens (trunk, tags, etc.). Si vous voulez faire en sorte que le
sous-répertoire trunk soit la nouvelle racine de votre projet pour
tous les commits, filter-branch peut aussi vous aider à le faire :
$ git filter-branch --subdirectory-filter trunk HEAD
Rewrite 856f0bf61e41a27326cdae8f09fe708d679f596f (12/12)
Ref 'refs/heads/master' was rewritten
Maintenant votre nouvelle racine est remplacée par le contenu du
répertoire trunk. De plus, Git supprimera automatiquement les
commits qui n’affectent pas ce sous-répertoire.
Modifier globalement l’adresse mail
Un autre cas habituel est que vous oubliez d’exécuter git config pour
configurer votre nom et votre adresse mail avant de commencer à
travailler, ou vous voulez peut-être rendre un projet du boulot open
source et donc changer votre adresse professionnelle pour celle
personnelle. Dans tous les cas, vous pouvez modifier l’adresse mail dans
plusieurs commits avec un script filter-branch. Vous devez faire
attention de ne changer que votre adresse mail, utilisez donc
--commit-filter :
$ git filter-branch --commit-filter '
if [ "$GIT_AUTHOR_EMAIL" = "schacon@localhost" ];
then
GIT_AUTHOR_NAME="Scott Chacon";
GIT_AUTHOR_EMAIL="schacon@example.com";
git commit-tree "$@";
else
git commit-tree "$@";
fi' HEAD
Cela passe sur chaque commit et le réécrit pour avoir votre nouvelle adresse. Mais puisque les commits contiennent l’empreinte SHA-1 de leur parent, cette commande modifie tous les commits dans votre historique, pas seulement ceux correspondant à votre adresse mail.
Reset démystifié
Avant d’aborder des outils plus spécialisés, parlons un instant de
reset et checkout. Ces commandes sont deux des plus grandes sources
de confusion à leur premier contact. Elles permettent de faire tant de
choses et il semble impossible de les comprendre et les employer
correctement. Pour ceci, nous vous recommandons une simple métaphore.
Les trois arbres
Le moyen le plus simple de penser à reset et checkout consiste à
représenter Git comme un gestionnaire de contenu de trois arborescences
différentes. Par « arborescence », il faut comprendre « collection de
fichiers », pas spécifiquement structure de données. Il existe quelques
cas pour lesquels l’index ne se comporte pas exactement comme une
arborescence, mais pour ce qui nous concerne, c’est plus simple de
l’imaginer de cette manière pour le moment.
Git, comme système, gère et manipule trois arbres au cours de son opération normale :
| Arbre | Rôle |
|---|---|
HEAD |
instantané de la dernière validation, prochain parent |
Index |
instantané proposé de la prochaine validation |
Répertoire de travail |
bac à sable |
HEAD
HEAD est un pointeur sur la référence de la branche actuelle, qui est à son tour un pointeur sur le dernier commit réalisé sur cette branche. Ceci signifie que HEAD sera le parent du prochain commit à créer. C’est généralement plus simple de penser HEAD comme l’instantané de votre dernière validation.
En fait, c’est assez simple de visualiser ce à quoi cet instantané ressemble. Voici un exemple de liste du répertoire et des sommes de contrôle SHA-1 pour chaque fichier de l’instantané HEAD :
$ git cat-file -p HEAD
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
author Scott Chacon 1301511835 -0700
committer Scott Chacon 1301511835 -0700
initial commit
$ git ls-tree -r HEAD
100644 blob a906cb2a4a904a152... README
100644 blob 8f94139338f9404f2... Rakefile
040000 tree 99f1a6d12cb4b6f19... lib
Les commandes cat-file et ls-tree sont des commandes de
« plomberie » qui sont utilisées pour des activités de base niveau et ne
sont pas réellement utilisées pour le travail quotidien, mais elles nous
permettent de voir ce qui se passe ici.
L’index
L’index est votre prochain commit proposé. Nous avons aussi fait
référence à ce concept comme la « zone de préparation » de Git du fait
que c’est ce que Git examine lorsque vous lancez git commit.
Git remplit cet index avec une liste de tous les contenus des fichiers
qui ont été extraits dans votre copie de travail et ce qu’ils
contenaient quand ils ont été originellement extraits. Vous pouvez alors
remplacer certains de ces fichiers par de nouvelles versions de ces
mêmes fichiers, puis git commit convertit cela en arborescence du
nouveau commit.
$ git ls-files -s
100644 a906cb2a4a904a152e80877d4088654daad0c859 0 README
100644 8f94139338f9404f26296befa88755fc2598c289 0 Rakefile
100644 47c6340d6459e05787f644c2447d2595f5d3a54b 0 lib/simplegit.rb
Encore une fois, nous utilisons ici ls-files qui est plus une commande
de coulisses qui vous montre l’état actuel de votre index.
L’index n’est pas techniquement parlant une structure arborescente ‑ c’est en fait un manifeste aplati ‑ mais pour nos besoins, c’est suffisamment proche.
Le répertoire de travail
Finalement, vous avez votre répertoire de travail. Les deux autres
arbres stockent leur contenu de manière efficace mais peu pratique dans
le répertoire .git. Le répertoire de travail les dépaquette comme
fichiers réels, ce qui rend tout de même plus facile leur modification.
Il faut penser à la copie de travail comme un bac à sable où vous
pouvez essayer vos modifications avant de les transférer dans votre
index puis le valider dans votre historique.
$ tree
.
├── README
├── Rakefile
└── lib
└── simplegit.rb
1 directory, 3 files
Le flux de travail
L’objet principal de Git est d’enregistrer des instantanés de votre projet comme des états successifs évolutifs en manipulant ces trois arbres.
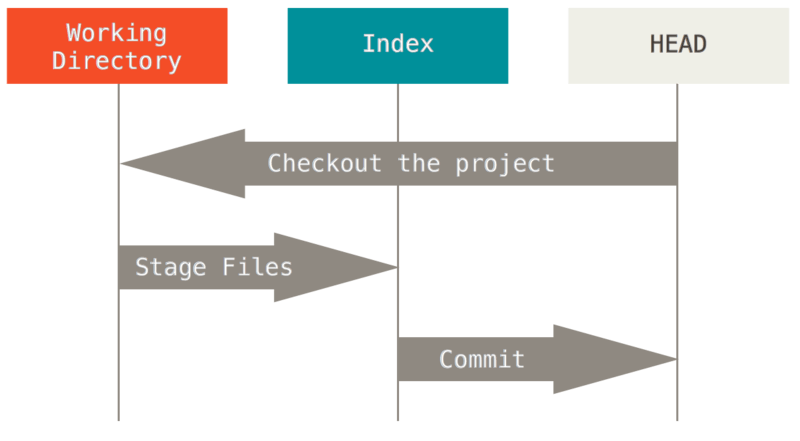
Visualisons ce processus : supposons que vous allez dans un nouveau
répertoire contenant un fichier unique. Nous appellerons ceci v1 du
fichier et nous le marquerons en bleu. Maintenant, nous allons lancer
git init, ce qui va créer le dépôt Git avec une référence HEAD qui
pointe sur une branche à naître (master n’existe pas encore).
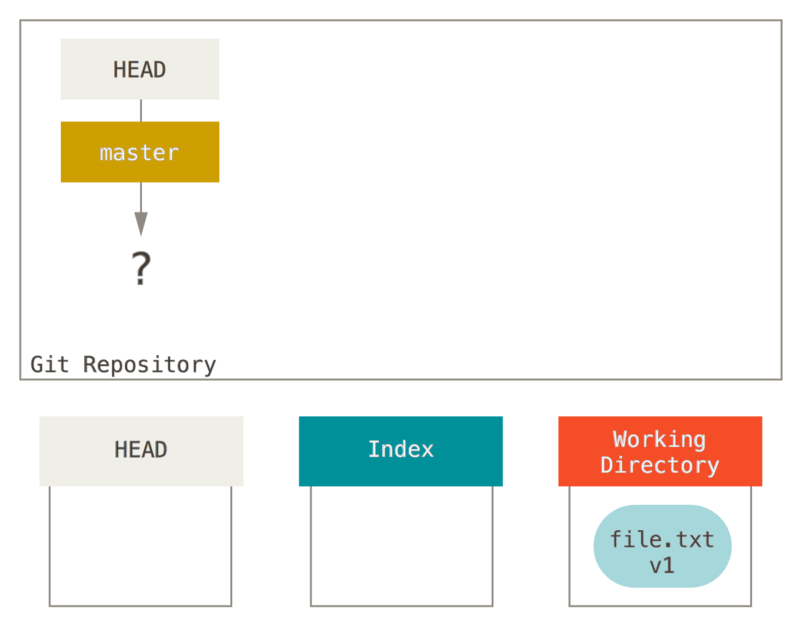
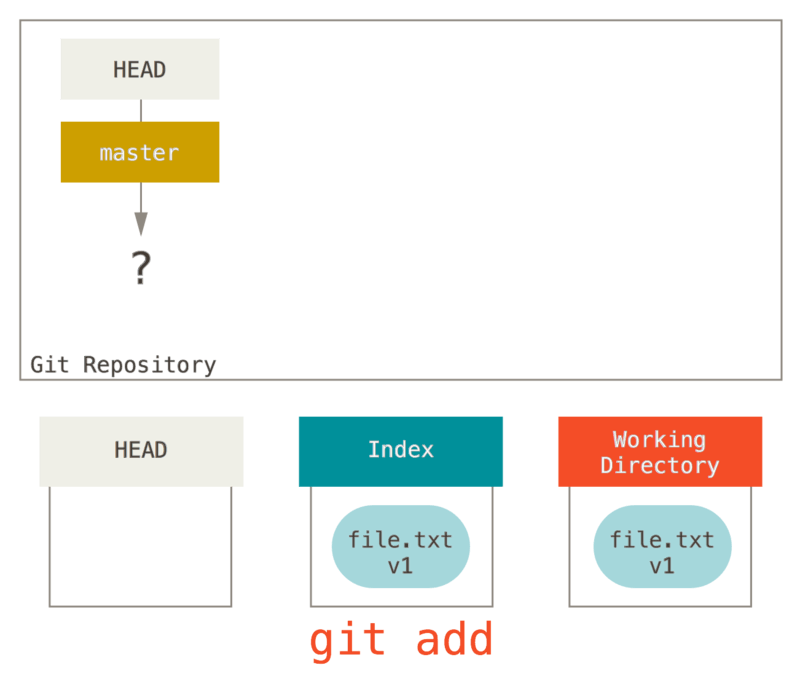
À ce point, seul le répertoire de travail contient quelque chose.
Maintenant, nous souhaitons valider ce fichier, donc nous utilisons
git add qui prend le contenu du répertoire de travail et le copie dans
l’index.
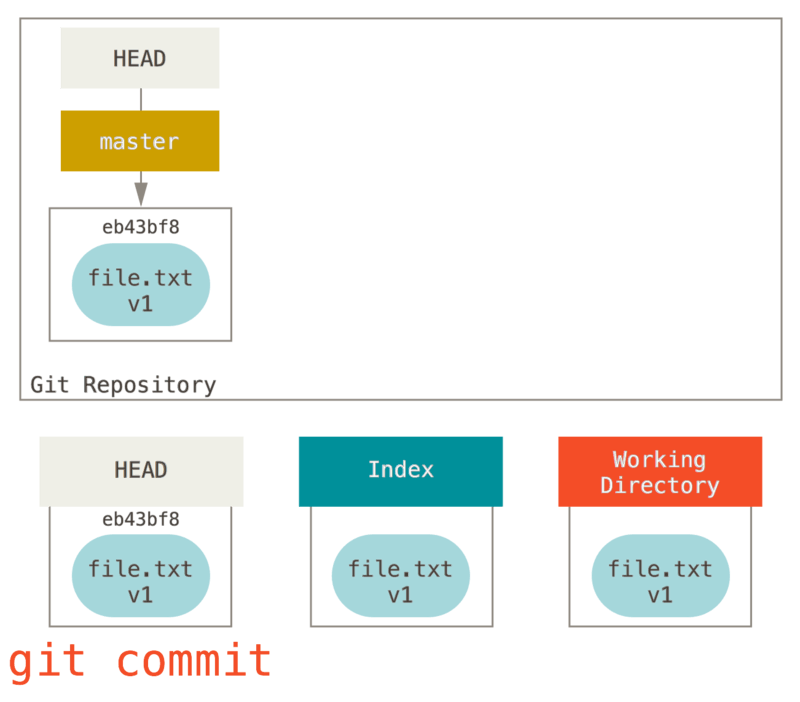
Ensuite, nous lançons git commit, ce qui prend le contenu de l’index
et le sauve comme un instantané permanent, crée un objet commit qui
pointe sur cet instantané et met à jour master pour pointer sur ce
commit.
Si nous lançons git status, nous ne verrons aucune modification parce
que les trois arborescences sont identiques.
Maintenant, nous voulons faire des modifications sur ce fichier et le valider. Nous suivons le même processus ; en premier nous changeons le fichier dans notre copie de travail. Appelons cette version du fichier v2 et marquons-le en rouge.
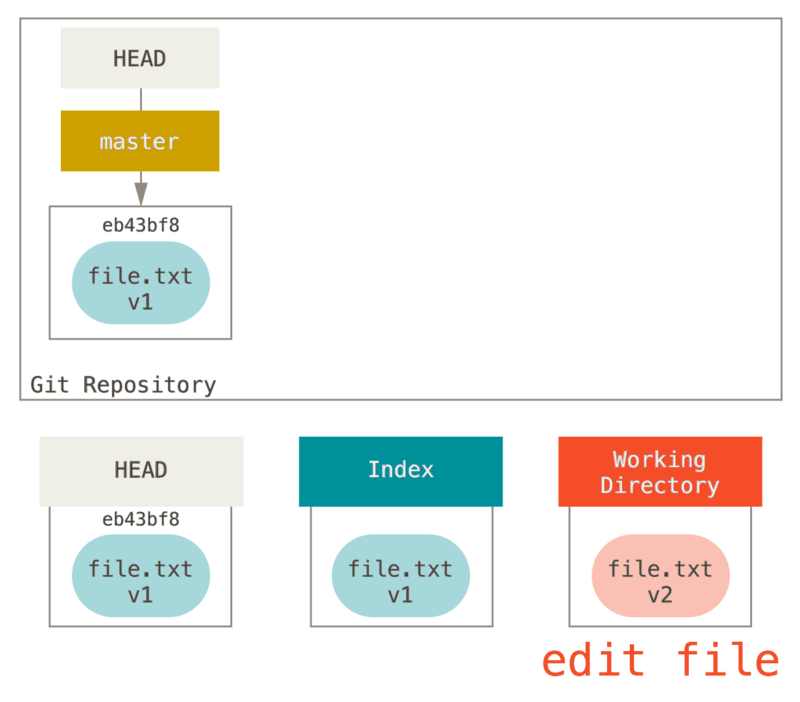
Si nous lançons git status maintenant, nous verrons le fichier en
rouge comme « Modifications qui ne seront pas validées » car cette
entrée est différente entre l’index et le répertoire de travail.
Ensuite, nous lançons git add dessus pour le monter dans notre index.
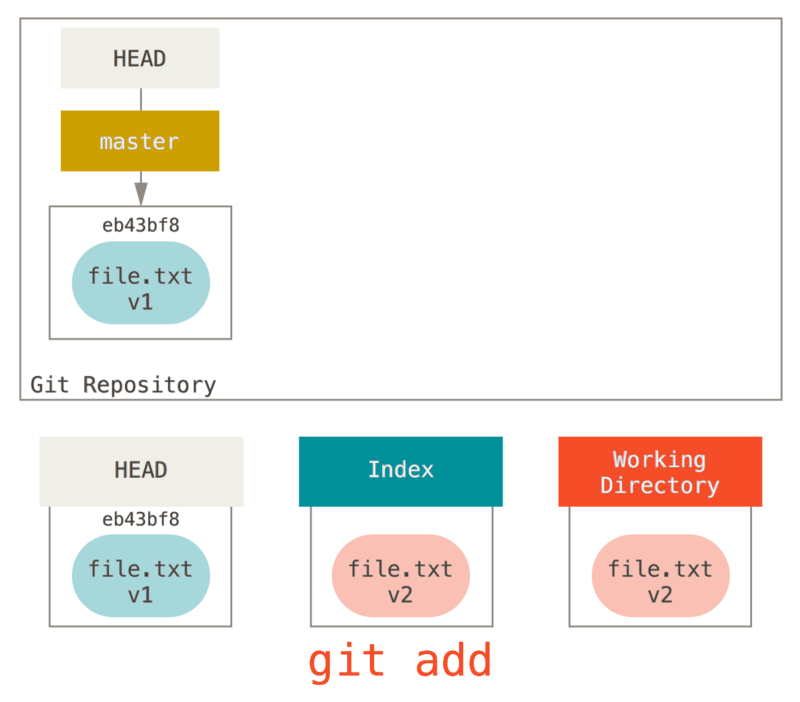
À ce point, si nous lançons git status, nous verrons le fichier en
vert sous « Modifications qui seront validées » parce que l’index et
HEAD diffèrent, c’est-à-dire que notre prochain commit proposé est
différent de notre dernier commit. Finalement, nous lançons
git commit pour finaliser la validation.
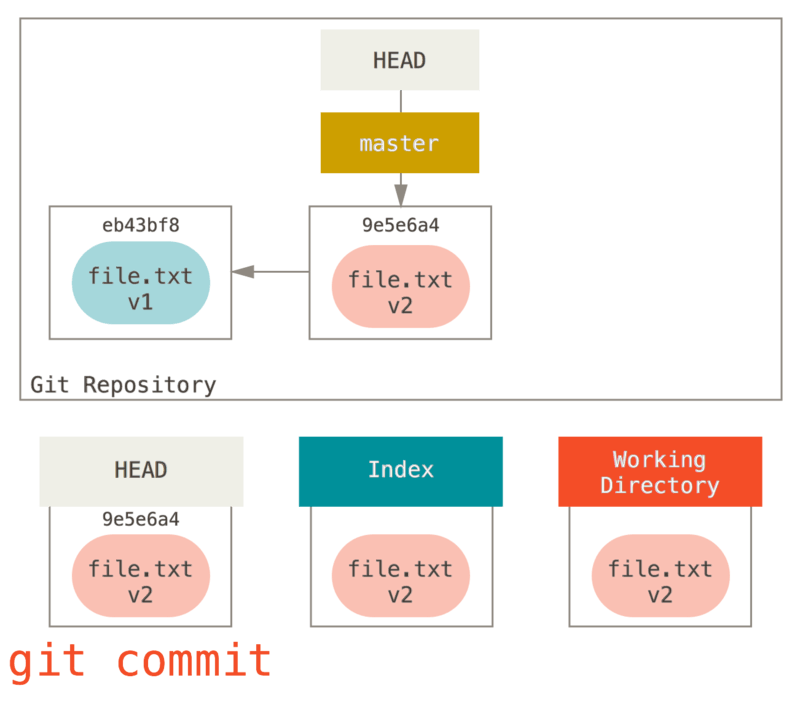
Maintenant, git status n’indique plus rien, car les trois
arborescences sont à nouveau identiques.
Les basculements de branches ou les clonages déroulent le même processus. Quand vous extrayez une branche, cela change HEAD pour pointer sur la nouvelle référence de branche, popule votre index avec l’instantané de ce commit, puis copie le contenu de l’index dans votre répertoire de travail.
Le rôle de reset
La commande reset est plus compréhensible dans ce contexte.
Pour l’objectif des exemples à suivre, supposons que nous avons modifié
file.txt à nouveau et validé une troisième fois. Donc maintenant,
notre historique ressemble à ceci :
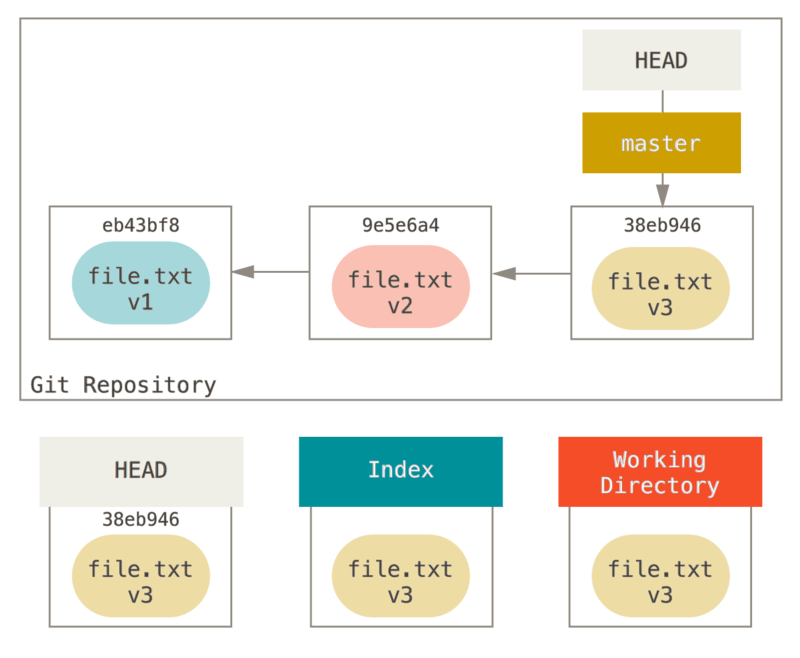
Détaillons maintenant ce que reset fait lorsque vous l’appelez. Il
manipule directement les trois arborescences d’une manière simple et
prédictible. Il réalise jusqu’à trois opérations basiques.
Étape 1: déplacer HEAD
La première chose que reset va faire consiste à déplacer ce qui est
pointé par HEAD. Ce n’est pas la même chose que changer HEAD lui-même
(ce que fait checkout). reset déplace la branche que HEAD pointe.
Ceci signifie que si HEAD est pointé sur la branche master (par
exemple, si vous êtes sur la branche master), lancer
git reset 9e5e6a4 va commencer par faire pointer master sur
9e5e6a4.
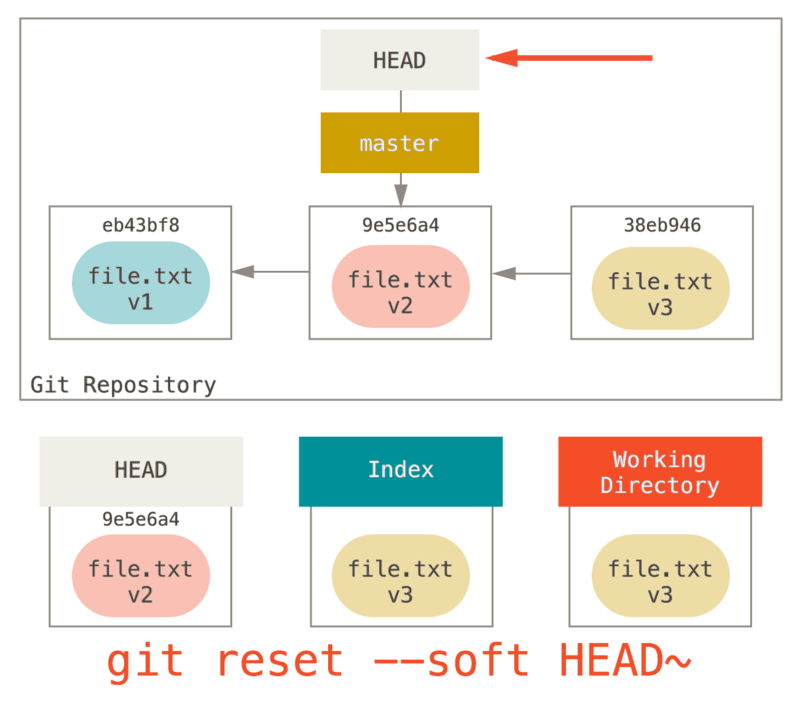
Quelle que soit la forme du reset que vous invoquez pour un commit,
ce sera toujours la première chose qu’il tentera de faire. Avec
reset --soft, il n’ira pas plus loin.
Maintenant, arrêtez-vous une seconde et regardez le diagramme ci-dessus
pour comprendre ce qu’il s’est passé : en essence, il a défait ce que la
dernière commande git commit a créé. Quand vous lancez git commit,
Git crée un nouvel objet commit et déplace la branche pointée par HEAD
dessus. Quand vous faites un reset sur HEAD~ (le parent de HEAD),
vous replacez la branche où elle était, sans changer ni l’index ni la
copie de travail. Vous pourriez maintenant mettre à jour l’index et
relancer git commit pour accomplir ce que git commit --amend aurait
fait (voir Modifier la dernière validation).
Étape 2 : Mise à jour de l’index (--mixed)
Notez que si vous lancez git status maintenant, vous verrez en vert la
différence entre l’index et le nouveau HEAD.
La chose suivante que reset réalise est de mettre à jour l’index avec
le contenu de l’instantané pointé par HEAD.
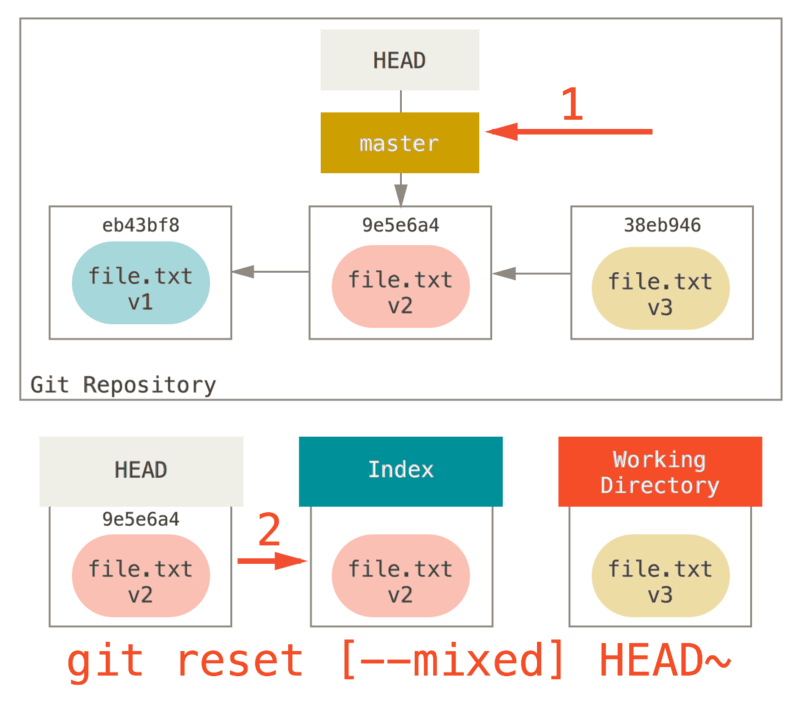
Si vous spécifiez l’option --mixed, reset s’arrêtera à cette étape.
C’est aussi le comportement par défaut, donc si vous ne spécifiez aucune
option (juste git reset HEAD~ dans notre cas), c’est ici que la
commande s’arrêtera.
Maintenant arrêtez-vous encore une seconde et regardez le diagramme
ci-dessus pour comprendre ce qui s’est passé : il a toujours défait la
dernière validation, mais il a aussi tout désindéxé. Vous êtes revenu
à l’état précédant vos commandes git add et git commit.
Étape 3: Mise à jour de la copie de travail (--hard)
La troisième chose que reset va faire est de faire correspondre la
copie de travail avec l’index. Si vous utilisez l’option --hard, il
continuera avec cette étape.
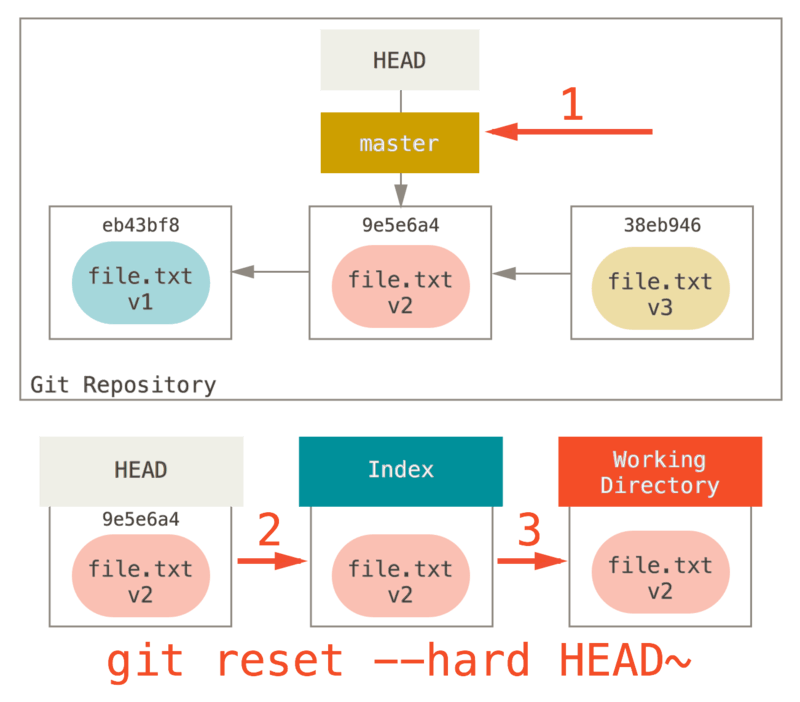
Donc réfléchissons à ce qui vient d’arriver. Vous avez défait la
dernière validation, les commandes git add et git commit ainsi
que tout le travail que vous avez réalisé dans le répertoire de
travail.
Il est important de noter que cette option (--hard) est le seul moyen
de rendre la commande reset dangereuse et est un des très rares cas où
Git va réellement détruire de la donnée. Toute autre invocation de
reset peut être défaite, mais l’option --hard ne le permet pas, car
elle force l’écrasement des fichiers dans le répertoire de travail. Dans
ce cas particulier, nous avons toujours la version v3 du fichier
dans un commit dans notre base de donnée Git, et nous pourrions la
récupérer en parcourant notre reflog, mais si nous ne l’avions pas
validé, Git aurait tout de même écrasé les fichiers et rien n’aurait pu
être récupéré.
Récapitulatif
La commande reset remplace ces trois arbres dans un ordre spécifique,
s’arrêtant lorsque vous lui indiquez :
Déplace la branche pointée par HEAD (s’arrête ici si
--soft)Fait ressembler l’index à HEAD (s’arrête ici à moins que
--hard)Fait ressembler le répertoire de travail à l’index.
Reset avec un chemin
Tout cela couvre le comportement de reset dans sa forme de base, mais
vous pouvez aussi lui fournir un chemin sur lequel agir. Si vous
spécifiez un chemin, reset sautera la première étape et limitera la
suite de ses actions à un fichier spécifique ou à un ensemble de
fichiers. Cela fait sens ; en fait, HEAD n’est rien de plus qu’un
pointeur et vous ne pouvez pas pointer sur une partie d’un commit et
une partie d’un autre. Mais l’index et le répertoire de travail
peuvent être partiellement mis à jour, donc reset continue avec les
étapes 2 et 3.
Donc, supposons que vous lancez git reset file.txt. Cette forme
(puisque vous n’avez pas spécifié un SHA-1 de commit ni de branche, et
que vous n’avez pas non plus spécifié --soft ou --hard) est un
raccourcis pour git reset --mixed HEAD file.txt, qui va :
déplacer la branche pointée par HEAD (sauté)
faire ressembler l’index à HEAD (s’arrête ici)
Donc, en substance, il ne fait que copier file.txt de HEAD vers index.
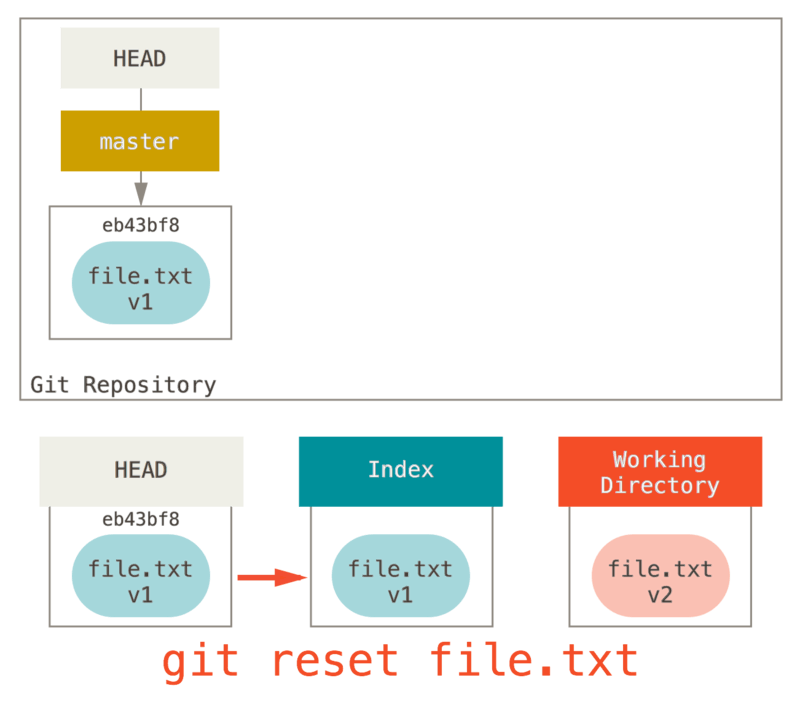
Ceci a l’effet pratique de désindexer le fichier. Si on regarde cette
commande dans le diagramme et qu’on pense à ce que git add fait, ce
sont des opposés exacts.
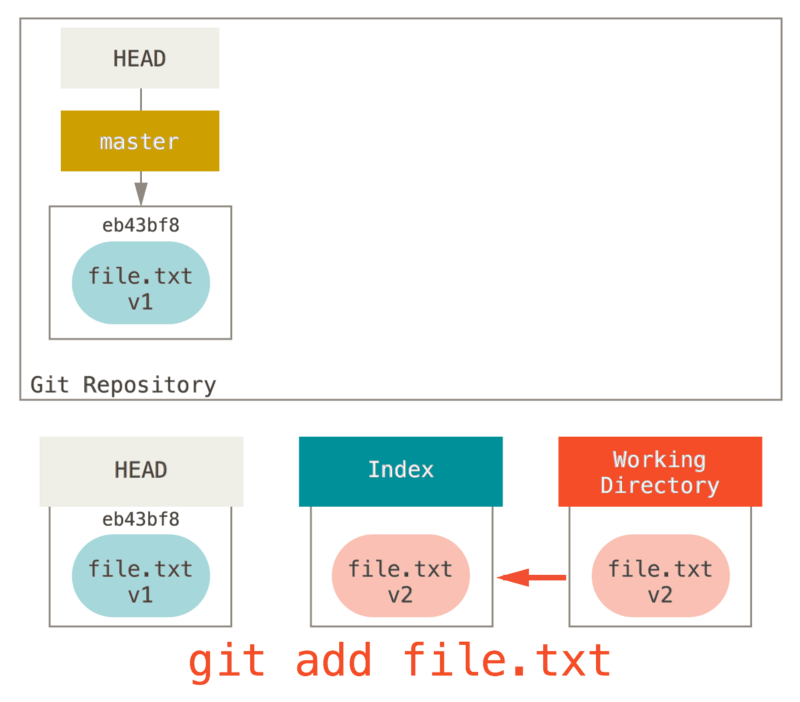
C’est pourquoi le résultat de la commande git status suggère que vous
lanciez cette commande pour désindexer le fichier (voir Désindexer un
fichier déjà indexé pour plus de détail).
Nous pourrions tout aussi bien ne pas laisser Git considérer que nous
voulions dire « tirer les données depuis HEAD » en spécifiant un
commit spécifique d’où tirer ce fichier. Nous lancerions juste quelque
chose comme git reset eb43bf file.txt.
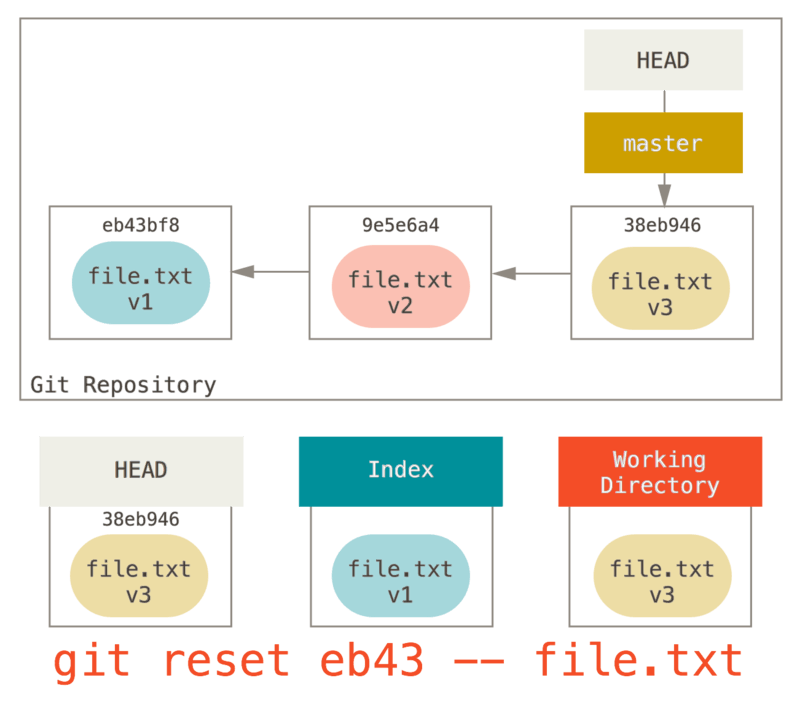
Ceci fait effectivement la même chose que si nous remettions le contenu
du fichier à la v1 dans le répertoire de travail, lancions git add
dessus, puis le ramenions à nouveau à la v3 (sans forcément passer
par toutes ces étapes). Si nous lançons git commit maintenant, il
enregistrera la modification qui remet le fichier à la version v1,
même si nous ne l’avons jamais eu à nouveau dans notre répertoire de
travail.
Il est intéressant de noter que comme git add, la commande reset
accepte une option --patch pour désindexer le contenu section par
section. Vous pouvez donc sélectivement désindexer ou ramener du
contenu.
Écraser les commits
Voyons comment faire quelque chose d’intéressant avec ce tout nouveau pouvoir - écrasons des commits.
Supposons que vous avez une série de commits contenant des messages
tels que « oups », « en chantier » ou « ajout d’un fichier manquant ».
Vous pouvez utiliser reset pour les écraser tous rapidement et
facilement en une seule validation qui vous donne l’air vraiment
intelligent (Écraser un commit explique un autre moyen
de faire pareil, mais dans cet exemple, c’est plus simple de faire un
reset).
Disons que vous avez un projet où le premier commit contient un fichier, le second commit a ajouté un nouveau fichier et a modifié le premier, et le troisième a remodifié le premier fichier. Le second commit était encore en chantier et vous souhaitez le faire disparaître.
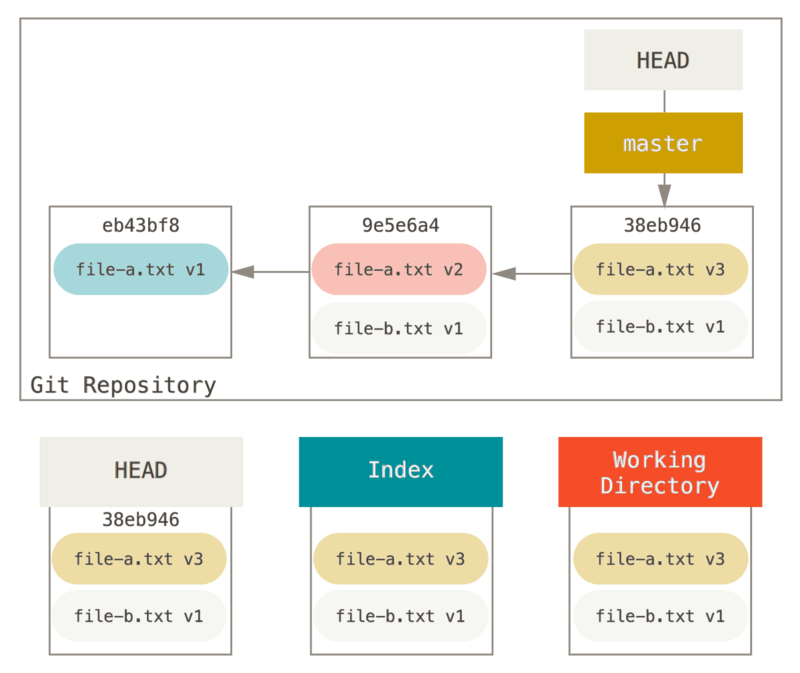
Vous pouvez lancer git reset --soft HEAD~2 pour ramener la branche de
HEAD sur l’ancien commit (le premier commit que vous souhaitez
garder) :
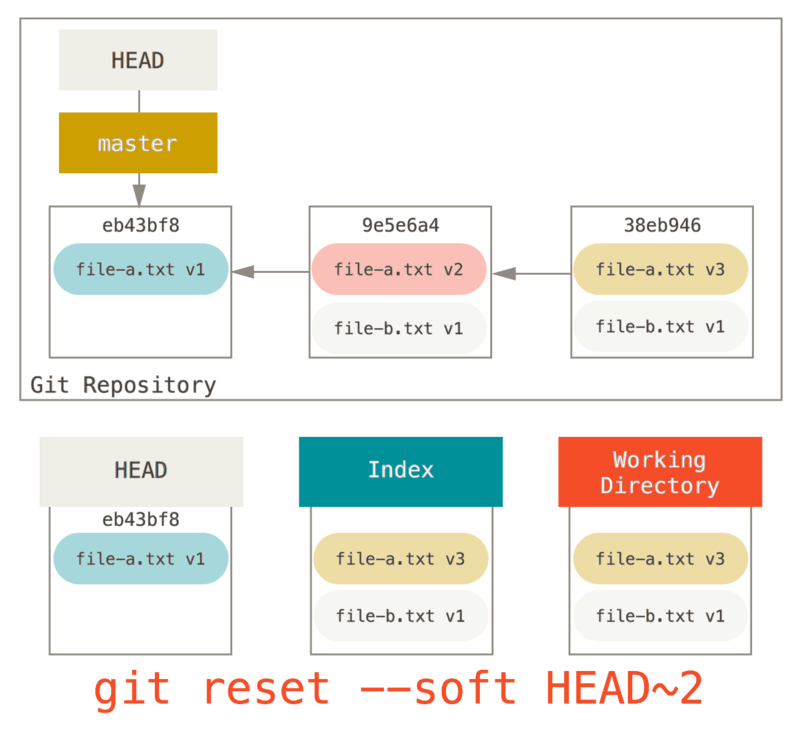
Ensuite, relancez simplement git commit :
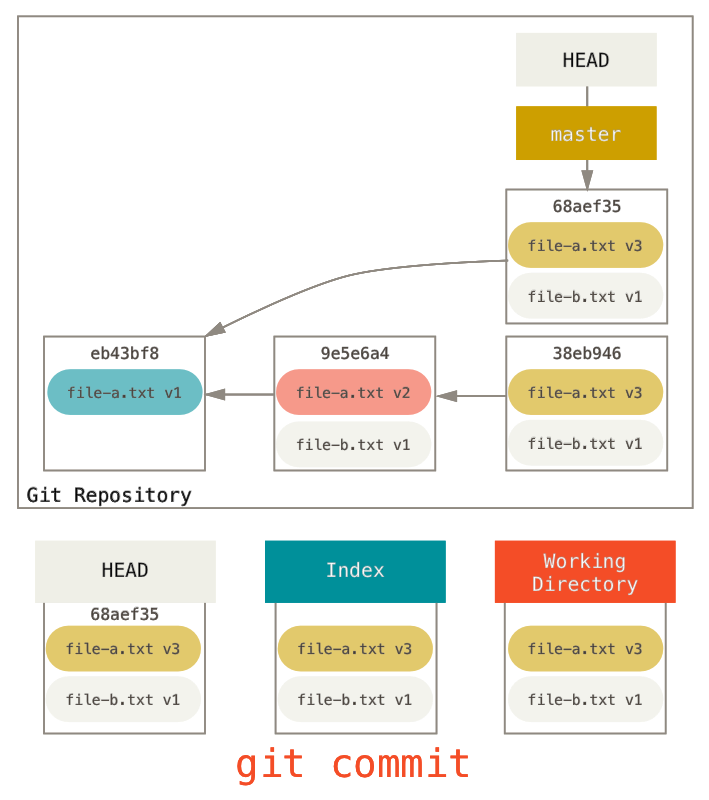
Maintenant vous pouvez voir que votre historique accessible,
l’historique que vous pousseriez, ressemble à présent à un premier
commit avec le fichier file-a.txt v1, puis un second qui modifie à
la fois file-a.txt à la version 3 et ajoute file-b.txt. Le commit
avec la version v2 du fichier ne fait plus partie de l’historique.
Et checkout
Finalement, vous pourriez vous demander quelle différence il y a entre
checkout et reset. Comme reset, checkout manipule les trois
arborescences et se comporte généralement différemment selon que vous
indiquez un chemin vers un fichier ou non.
Sans chemin
Lancer git checkout [branche] est assez similaire à lancer
git reset --hard [branche] en ce qu’il met à jour les trois
arborescences pour qu’elles ressemblent à [branche], mais avec deux
différences majeures.
Premièrement, à la différence de reset --hard, checkout préserve le
répertoire de travail ; il s’assure de ne pas casser des fichiers qui
ont changé. En fait, il est même un peu plus intelligent que ça – il
essaie de faire une fusion simple dans le répertoire de travail, de
façon que tous les fichiers non modifiés soient mis à jour.
reset --hard, par contre, va simplement tout remplacer unilatéralement
sans rien vérifier.
La seconde différence majeure concerne sa manière de mettre à jour HEAD.
Là où reset va déplacer la branche pointée par HEAD, checkout va
déplacer HEAD lui-même pour qu’il pointe sur une autre branche.
Par exemple, supposons que nous avons des branches master et develop
qui pointent sur des commits différents et que nous sommes
actuellement sur develop (donc HEAD pointe dessus). Si nous lançons
git reset master, develop lui-même pointera sur le même commit que
master. Si nous lançons plutôt git checkout master, develop ne va
pas bouger, seul HEAD va changer. HEAD pointera alors sur master.
Donc, dans les deux cas, nous déplaçons HEAD pour pointer sur le commit
A, mais la manière diffère beaucoup. reset va déplacer la branche
pointée par HEAD, alors que checkout va déplacer HEAD lui-même.
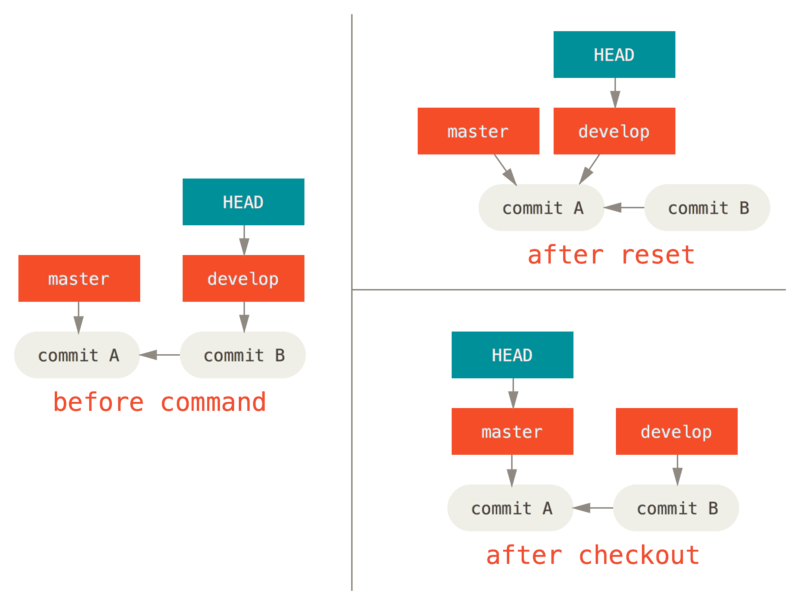
Avec des chemins
L’autre façon de lancer checkout est avec un chemin de fichier, ce
qui, comme reset, ne déplace pas HEAD. Cela correspond juste à
git reset [branche] fichier car cela met à jour l’index avec ce
fichier à ce commit, mais en remplaçant le fichier dans le répertoire
de travail. Ce serait exactement comme
git reset --hard [branche] fichier (si reset le permettait) – cela
ne préserve pas le répertoire de travail et ne déplace pas non plus
HEAD.
De même que git reset et git add, checkout accepte une option
--patch permettant de réinitialiser sélectivement le contenu d’un
fichier section par section.
Résumé
J’espère qu’à présent vous comprenez mieux et vous sentez plus à l’aise
avec la commande reset, même si vous pouvez vous sentir encore un peu
confus sur ce qui la différencie exactement de checkout et avoir du
mal à vous souvenir de toutes les règles de ses différentes invocations.
Voici un aide-mémoire sur ce que chaque commande affecte dans chaque arborescence. La colonne « HEAD » contient « RÉF » si cette commande déplace la référence (branche) pointée par HEAD, et « HEAD » si elle déplace HEAD lui-même. Faites particulièrement attention à la colonne « préserve RT ? » (préserve le répertoire de travail) – si elle indique NON, réfléchissez à deux fois avant de lancer la commande.
| HEAD | Index | Rép. Travail | préserve RT ? | |
|---|---|---|---|---|
Niveau commit |
||||
|
RÉF |
NON |
NON |
OUI |
|
RÉF |
OUI |
NON |
OUI |
|
RÉF |
OUI |
OUI |
NON |
|
HEAD |
OUI |
OUI |
OUI |
Niveau Fichier |
||||
|
NON |
OUI |
NON |
OUI |
|
NON |
OUI |
OUI |
NON |
Fusion avancée
La fusion avec Git est généralement plutôt facile. Puisque Git rend facile la fusion d’une autre branche plusieurs fois, cela signifie que vous pouvez avoir une branche à très longue durée de vie que vous pouvez mettre à jour au fil de l’eau, en résolvant souvent les petits conflits plutôt que d’être surpris par un énorme conflit à la fin de la série.
Cependant, il arrive quelques fois des conflits compliqués. À la différence d’autres systèmes de contrôle de version, Git n’essaie pas d’être plus intelligent que de mesure pour la résolution des conflits. La philosophie de Git, c’est d’être malin pour déterminer lorsque la fusion est sans ambiguïté mais s’il y a un conflit, il n’essaie pas d’être malin pour le résoudre automatiquement. De ce fait, si vous attendez trop longtemps pour fusionner deux branches qui divergent rapidement, vous rencontrerez des problèmes.
Dans cette section, nous allons détailler ce que certains de ces problèmes peuvent être et quels outils Git vous offre pour vous aider à gérer ces situations délicates. Nous traiterons aussi quelques types de fusions différents, non-standard, ainsi que la manière de mémoriser les résolutions que vous avez déjà réalisées.
Conflits de fusion
Bien que nous avons couvert les bases de la résolution de conflits dans Conflits de fusions (Merge conflicts), pour des conflits plus complexes, Git fournit quelques outils pour vous aider à vous y retrouver et à mieux gérer les conflits.
Premièrement, si c’est seulement possible, essayer de démarrer d’un répertoire de travail propre avant de commencer une fusion qui pourrait engendrer des conflits. Si vous avez un travail en cours, validez-le dans une branche temporaire ou remisez-le. Cela vous permettra de défaire tout ce que vous pourrez essayer. Si vous avez des modifications non sauvegardées dans votre répertoire de travail quand vous essayez une fusion, certaines des astuces qui vont suivre risque de vous faire perdre ce travail.
Parcourons ensemble un exemple très simple. Nous avons un fichier Ruby super simple qui affiche « hello world ».
#! /usr/bin/env ruby
def hello
puts 'hello world'
end
hello()
Dans notre dépôt, nous créons une nouvelle branche appelée whitespace
et nous entamons la transformation de toutes les fins de ligne Unix en
fin de lignes DOS, ce qui revient à modifier chaque ligne, mais juste
avec des caractères invisibles. Ensuite, nous changeons la ligne « hello
world » en « hello mundo ».
$ git checkout -b whitespace
Basculement sur la nouvelle branche 'whitespace'
$ unix2dos hello.rb
unix2dos: converting file hello.rb to DOS format ...
$ git commit -am 'converted hello.rb to DOS'
[whitespace 3270f76] converted hello.rb to DOS
1 file changed, 7 insertions(+), 7 deletions(-)
$ vim hello.rb
$ git diff -w
diff --git a/hello.rb b/hello.rb
index ac51efd..e85207e 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,7 +1,7 @@
#! /usr/bin/env ruby
def hello
- puts 'hello world'
+ puts 'hello mundo'^M
end
hello()
$ git commit -am 'hello mundo change'
[whitespace 6d338d2] hello mundo change
1 file changed, 1 insertion(+), 1 deletion(-)
À présent, nous rebasculons sur master et nous ajoutons une
documentation de la fonction.
$ git checkout master
Basculement sur la branche 'master'
$ vim hello.rb
$ git diff
diff --git a/hello.rb b/hello.rb
index ac51efd..36c06c8 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,5 +1,6 @@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
puts 'hello world'
end
$ git commit -am 'document the function'
[master bec6336] document the function
1 file changed, 1 insertion(+)
Et maintenant, nous essayons de fusionner notre branche whitespace et
nous allons générer des conflits dûs aux modifications de fins de ligne.
$ git merge whitespace
Fusion automatique de hello.rb
CONFLIT (contenu) : Conflit de fusion dans hello.rb
La fusion automatique a échoué ; réglez les conflits et validez le résultat.
Abandonner une fusion
Nous avons ici plusieurs options. Une première consiste à sortir de
cette situation. Vous ne vous attendiez peut-être pas à rencontrer un
conflit et vous ne souhaitez pas encore le gérer, alors vous pouvez
simplement faire marche arrière avec git merge --abort.
$ git status -sb
## master
UU hello.rb
$ git merge --abort
$ git status -sb
## master
L’option git merge --abort essaie de vous ramener à l’état précédent
la fusion. Les seuls cas dans lesquels il n’y parvient pas parfaitement
seraient ceux pour lesquels vous aviez déjà auparavant des modifications
non validées ou non remisées dans votre répertoire de travail au moment
de la fusion. Sinon, tout devrait se passer sans problème.
Si, pour une raison quelconque, vous vous trouvez dans une situation
horrible et que vous souhaitez repartir à zéro, vous pouvez aussi lancer
git reset --hard HEAD ou sur toute autre référence où vous souhaitez
revenir. Souvenez-vous tout de même que cela va balayer toutes les
modifications de votre répertoire de travail, donc assurez-vous de
n’avoir aucune modification de valeur avant.
Ignorer les caractères invisibles
Dans ce cas spécifique, les conflits sont dûs à des espaces blancs. Nous le savons parce que le cas est simple, mais cela reste assez facile à déterminer dans les cas réels en regardant les conflits parce que chaque ligne est supprimée à une ligne puis réintroduite à la suivante. Par défaut, Git voit toutes ces lignes comme modifiées et il ne peut pas fusionner les fichiers.
La stratégie de fusion par défaut accepte quand même des arguments, et
certains d’entre eux traitent le cas des modifications impliquant les
caractères blancs. Si vous vous rendez compte que vous avez de nombreux
conflits de caractères blancs lors d’une fusion, vous pouvez simplement
abandonner la fusion et en relancer une en utilisant les options
-Xignore-all-space ou -Xignore-space-change. La première option
ignore complètement tous les espaces tandis que la seconde traite
les séquences d’un ou plusieurs espaces comme équivalentes.
$ git merge -Xignore-all-space whitespace
Fusion automatique de hello.rb
Merge made by the 'recursive' strategy.
hello.rb | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
Puisque dans ce cas, les modifications réelles n’entraient pas en conflit, une fois les modifications d’espaces ignorées, tout fusionne parfaitement bien.
Ça sauve la vie si vous avez dans votre équipe une personne qui reformate tout d’espaces en tabulations ou vice-versa.
Re-fusion manuelle d’un fichier
Bien que Git gère le pré-traitement d’espaces plutôt bien, il existe d’autres types de modifications que Git ne peut pas gérer automatiquement, mais dont la fusion peut être scriptable. Par exemple, supposons que Git n’ait pas pu gérer les espaces et que nous ayons dû résoudre le problème à la main.
Ce que nous devons réellement faire est de passer le fichier que nous
cherchons à fusionner à travers dos2unix avant d’essayer de le
fusionner réellement. Comment pourrions-nous nous y prendre ?
Premièrement, nous entrons dans l’état de conflit de fusion. Puis, nous voulons obtenir des copies de la version locale (ours), de la version distante (theirs, celle qui vient de la branche à fusionner) et de la version commune (l’ancêtre commun depuis lequel les branches sont parties). Ensuite, nous voulons corriger au choix la version locale ou la distante et réessayer de fusionner juste ce fichier.
Obtenir les trois versions des fichiers est en fait assez facile. Git
stocke toutes ces versions dans l’index sous formes d’étapes
(stages), auxquelles chacune y a un nombre associé. Stage 1 est
l’ancêtre commun, stage 2 est notre version, stage 3 est la version de
MERGE_HEAD, la version qu’on cherche à fusionner (theirs).
Vous pouvez extraire une copie de chacune de ces versions du fichier en
conflit avec la commande git show et une syntaxe spéciale.
$ git show :1:hello.rb > hello.common.rb
$ git show :2:hello.rb > hello.ours.rb
$ git show :3:hello.rb > hello.theirs.rb
Si vous voulez rentrer un peu plus dans le dur, vous pouvez aussi
utiliser la commande de plomberie ls-files -u pour récupérer les SHA-1
des blobs Git de chacun de ces fichiers.
$ git ls-files -u
100755 ac51efdc3df4f4fd328d1a02ad05331d8e2c9111 1 hello.rb
100755 36c06c8752c78d2aff89571132f3bf7841a7b5c3 2 hello.rb
100755 e85207e04dfdd5eb0a1e9febbc67fd837c44a1cd 3 hello.rb
La syntaxe :1:hello.rb est juste un raccourcis pour la recherche du
SHA-1 de ce blob.
À présent que nous avons le contenu des trois étapes dans notre
répertoire de travail, nous pouvons réparer manuellement la copie
distante pour résoudre le problème d’espaces et re-fusionner le fichier
avec la commande méconnue git merge-file dont c’est l’exacte fonction.
$ dos2unix hello.theirs.rb
dos2unix: converting file hello.theirs.rb to Unix format ...
$ git merge-file -p \
hello.ours.rb hello.common.rb hello.theirs.rb > hello.rb
$ git diff -w
diff --cc hello.rb
index 36c06c8,e85207e..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,8 -1,7 +1,8 @@@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()
À ce moment, nous avons un fichier joliment fusionné. En fait, cela
fonctionne même mieux que l’option ignore-all-space parce que le
problème d’espace est corrigé avant la fusion plutôt que simplement
ignoré. Dans la fusion ignore-all-space, nous avons en fait obtenu
quelques lignes contenant des fins de lignes DOS, ce qui a mélangé les
styles.
Si vous voulez vous faire une idée avant de finaliser la validation sur
ce qui a réellement changé entre un côté et l’autre, vous pouvez
demander à git diff de comparer le contenu de votre répertoire de
travail que vous êtes sur le point de valider comme résultat de la
fusion avec n’importe quelle étape. Détaillons chaque comparaison.
Pour comparer votre résultat avec ce que vous aviez dans votre branche
avant la fusion, en d’autres termes, ce que la fusion a introduit, vous
pouvez lancer git diff --ours
$ git diff --ours
* Unmerged path hello.rb
diff --git a/hello.rb b/hello.rb
index 36c06c8..44d0a25 100755
--- a/hello.rb
+++ b/hello.rb
@@ -2,7 +2,7 @@
# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()
Donc nous voyons ici que ce qui est arrivé à notre branche, ce que nous introduisons réellement dans ce fichier avec cette fusion, n’est qu’une ligne modifiée.
Si nous voulons voir le résultat de la fusion modifiée depuis la version
distante, nous pouvons lancer git diff --theirs. Dans cet exemple et
le suivant, nous devons utiliser -w pour éliminer les espaces parce
que nous le comparons à ce qui est dans Git et non pas notre version
nettoyée hello.theirs.rb du fichier.
$ git diff --theirs -w
* Unmerged path hello.rb
diff --git a/hello.rb b/hello.rb
index e85207e..44d0a25 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,5 +1,6 @@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
puts 'hello mundo'
end
Enfin, nous pouvons voir comment le fichier a été modifié dans les deux
branches avec git diff --base.
$ git diff --base -w
* Unmerged path hello.rb
diff --git a/hello.rb b/hello.rb
index ac51efd..44d0a25 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,7 +1,8 @@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()
À ce point, nous pouvons utiliser la commande git clean pour éliminer
les fichiers supplémentaires maintenant inutiles que nous avons créés
pour notre fusion manuelle.
$ git clean -f
Suppression de hello.common.rb
Suppression de hello.ours.rb
Suppression de hello.theirs.rb
Examiner les conflits
Peut-être ne sommes-nous pas heureux de la résolution actuelle, ou bien l’édition à la main d’un côté ou des deux ne fonctionne pas correctement et nécessite plus de contexte.
Modifions un peu l’exemple. Pour cet exemple, nous avons deux branches à longue durée de vie qui comprennent quelques commits mais créent des conflits de contenu légitimes à la fusion.
$ git log --graph --oneline --decorate --all
* f1270f7 (HEAD, master) update README
* 9af9d3b add a README
* 694971d update phrase to hola world
| * e3eb223 (mundo) add more tests
| * 7cff591 add testing script
| * c3ffff1 changed text to hello mundo
|/
* b7dcc89 initial hello world code
Nous avons maintenant trois commits uniques qui n’existent que sur la
branche master et trois autres sur la branche mundo. Si nous
essayons de fusionner la branche mundo, nous obtenons un conflit.
$ git merge mundo
Fusion automatique de hello.rb
CONFLIT (contenu): Conflit de fusion dans hello.rb
La fusion automatique a échoué ; réglez les conflits et validez le résultat.
Nous souhaitons voir ce qui constitue le conflit de fusion. Si nous ouvrons le fichier, nous verrons quelque chose comme :
#! /usr/bin/env ruby
def hello
<<<<<<< HEAD
puts 'hola world'
======
puts 'hello mundo'
>>>>>>> mundo
end
hello()
Les deux côtés de la fusion on ajouté du contenu au fichier, mais certains commits ont modifié le fichier au même endroit, ce qui a causé le conflit.
Explorons quelques outils que vous avez à disposition pour déterminer comment ce conflit est apparu. Peut-être le moyen de résoudre n’est-il pas évident. Il nécessite plus de contexte.
Un outil utile est git checkout avec l’option --conflict. Il va
re-extraire le fichier et remplacer les marqueurs de conflit. Cela peut
être utile si vous souhaitez éliminer les marqueurs et essayer de
résoudre le conflit à nouveau.
Vous pouvez passer en paramètre à --conflict, soit diff3 soit
merge (le paramètre par défaut). Si vous lui passez diff3, Git
utilisera une version différente des marqueurs de conflit, vous
fournissant non seulement les versions locales (ours) et distantes
(theirs), mais aussi la version « base » intégrée pour vous fournir
plus de contexte.
$ git checkout --conflict=diff3 hello.rb
Une fois que nous l’avons lancé, le fichier ressemble à ceci :
#! /usr/bin/env ruby
def hello
<<<<<<< ours
puts 'hola world'
||||||| base
puts 'hello world'
======
puts 'hello mundo'
>>>>>>> theirs
end
hello()
Si vous appréciez ce format, vous pouvez le régler comme défaut pour les
futur conflits de fusion en renseignant le paramètre
merge.conflictstyle avec diff3.
$ git config --global merge.conflictstyle diff3
La commande git checkout peut aussi accepter les options --ours et
--theirs, qui peuvent servir de moyen rapide de choisir
unilatéralement une version ou une autre sans fusion.
Cela peut être particulièrement utile pour les conflits de fichiers binaires où vous ne pouvez que choisir un des côté, ou des conflits où vous souhaitez fusionner certains fichiers depuis d’autres branches - vous pouvez fusionner, puis extraire certains fichiers depuis un côté ou un autre avant de valider le résultat.
Journal de fusion
Un autre outil utile pour la résolution de conflits de fusion est
git log. Cela peut vous aider à obtenir du contexte ce qui a contribué
aux conflits. Parcourir un petit morceau de l’historique pour se
rappeler pourquoi deux lignes de développement ont touché au même
endroit dans le code peut s’avérer quelque fois très utile.
Pour obtenir une liste complète de tous les commits uniques qui ont été introduits dans chaque branche impliquée dans la fusion, nous pouvons utiliser la syntaxe « triple point » que nous avons apprise dans Triple point.
$ git log --oneline --left-right HEAD...MERGE_HEAD
< f1270f7 update README
< 9af9d3b add a README
< 694971d update phrase to hola world
> e3eb223 add more tests
> 7cff591 add testing script
> c3ffff1 changed text to hello mundo
Voilà une belle liste des six commits impliqués, ainsi que chaque ligne de développement sur laquelle chaque commit se trouvait.
Néanmoins, nous pouvons simplifier encore plus ceci pour fournir
beaucoup plus de contexte. Si nous ajoutons l’option --merge à
git log, il n’affichera que les commits de part et d’autre de la
fusion qui modifient un fichier présentant un conflit.
$ git log --oneline --left-right --merge
< 694971d update phrase to hola world
> c3ffff1 changed text to hello mundo
Si nous lançons cela avec l’option -p à la place, vous obtenez les
diffs limités au fichier qui s’est retrouvé en conflit. Cela peut
s’avérer vraiment utile pour vous donner le contexte nécessaire à la
compréhension de la raison d’un conflit et à sa résolution intelligente.
Format de diff combiné
Puisque Git indexe tous les résultats de fusion couronnés de succès,
quand vous lancez git diff dans un état de conflit de fusion, vous
n’obtenez que ce qui toujours en conflit à ce moment. Il peut s’avérer
utile de voir ce qui reste à résoudre.
Quand vous lancez git diff directement après le conflit de fusion, il
vous donne de l’information dans un format de diff plutôt spécial.
$ git diff
diff --cc hello.rb
index 0399cd5,59727f0..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,11 @@@
#! /usr/bin/env ruby
def hello
++<<<<<<< HEAD
+ puts 'hola world'
++=======
+ puts 'hello mundo'
++>>>>>>> mundo
end
hello()
Ce format s’appelle « diff combiné » (combined diff) et vous fournit deux colonnes d’information sur chaque ligne. La première colonne indique que la ligne est différente (ajoutée ou supprimée) entre la branche « ours » et le fichier dans le répertoire de travail. La seconde colonne fait de même pour la branche « theirs » et la copie du répertoire de travail.
Donc dans cet exemple, vous pouvez voir que les lignes <<<<<<< et
>>>>>>> sont dans la copie de travail mais n’étaient dans aucun des
deux côtés de la fusion. C’est logique parce que l’outil de fusion les a
collés ici pour donner du contexte, mais nous devrons les retirer.
Si nous résolvons le conflit et relançons git diff, nous verrons la
même chose, mais ce sera un peu plus utile.
$ vim hello.rb
$ git diff
diff --cc hello.rb
index 0399cd5,59727f0..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,7 @@@
#! /usr/bin/env ruby
def hello
- puts 'hola world'
- puts 'hello mundo'
++ puts 'hola mundo'
end
hello()
Ceci nous montre que « hola world » était présent de notre côté mais pas dans la copie de travail, que « hello mundo » était présent de l’autre côté mais pas non plus dans la copie de travail et que finalement, « hola mundo » n’était dans aucun des deux côtés, mais se trouve dans la copie de travail. C’est particulièrement utile lors d’une revue avant de valider la résolution.
Vous pouvez aussi l’obtenir depuis git log pour toute fusion pour
visualiser comment quelque chose a été résolu après coup. Git affichera
ce format si vous lancez git show sur un commit de fusion, ou si
vous ajoutez une option --cc à git log -p (qui par défaut ne montre
que les patchs des commits qui ne sont pas des fusions).
$ git log --cc -p -1
commit 14f41939956d80b9e17bb8721354c33f8d5b5a79
Merge: f1270f7 e3eb223
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Sep 19 18:14:49 2014 +0200
Merge branch 'mundo'
Conflicts:
hello.rb
diff --cc hello.rb
index 0399cd5,59727f0..e1d0799
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,7 @@@
#! /usr/bin/env ruby
def hello
- puts 'hola world'
- puts 'hello mundo'
++ puts 'hola mundo'
end
hello()
Défaire des fusions
Comme vous savez créer des commits de fusion à présent, vous allez certainement en faire par erreur. Un des grands avantages de l’utilisation de Git est qu’il n’est pas interdit de faire des erreurs, parce qu’il reste toujours possible (et très souvent facile) de les corriger.
Les commits de fusion ne font pas exception. Supposons que vous avez
commencé à travailler sur une branche thématique, que vous l’avez
accidentellement fusionnée dans master et qu’en conséquence votre
historique ressemble à ceci :
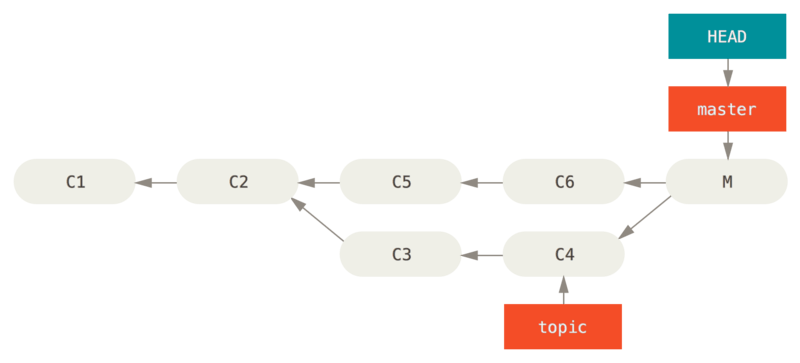
Figure 138. Commit de fusion accidentel
Il existe deux façons d’aborder ce problème, en fonction du résultat que vous souhaitez obtenir.
Correction des références
Si le commit de fusion non désiré n’existe que dans votre dépôt local,
la solution la plus simple et la meilleure consiste à déplacer les
branches pour qu’elles pointent où on le souhaite. La plupart du temps,
en faisant suivre le git merge malencontreux par un
git reset --hard HEAD~, on remet les pointeurs de branche dans l’état
suivant :
Figure 139. Historique après git reset --hard HEAD~
Nous avons détaillé reset dans Reset démystifié et il
ne devrait pas être très difficile de comprendre ce résultat. Voici
néanmoins un petit rappel : reset --hard réalise généralement trois
étapes :
Déplace la branche pointée par HEAD ; dans notre cas, nous voulons déplacer
mastersur son point avant la fusion (C6),Faire ressembler l’index à HEAD,
Faire ressembler le répertoire de travail à l’index.
Le défaut de cette approche est qu’elle ré-écrit l’historique, ce qui
peut être problématique avec un dépôt partagé. Reportez-vous à Les
dangers du rebasage pour plus d’information ; en
résumé si d’autres personnes ont déjà les commits que vous ré-écrivez,
il vaudrait mieux éviter un reset. Cette approche ne fonctionnera pas
non plus si d’autres commits ont été créés depuis la fusion ; déplacer
les références des branches éliminera effectivement ces modifications.
Inverser le commit
Si les déplacements des pointeurs de branche ne sont pas envisageables, Git vous donne encore l’option de créer un nouveau commit qui défait toutes les modifications d’un autre déjà existant. Git appelle cette option une « inversion » (revert), et dans ce scénario particulier, vous l’invoqueriez comme ceci :
$ git revert -m 1 HEAD
[master b1d8379] Revert "Merge branch 'topic'"
L’option -m 1 indique quel parent est le principal et devrait être
conservé. Si vous invoquez une fusion dans HEAD (git merge topic),
le nouveau commit a deux parents : le premier est HEAD (C6), et le
second est le sommet de la branche en cours de fusion (C4). Dans ce
cas, nous souhaitons défaire toutes les modifications introduites dans
le parent numéro 2 (C4), tout en conservant tout le contenu du parent
numéro 1 (C6).
L’historique avec le commit d’inversion ressemble à ceci :
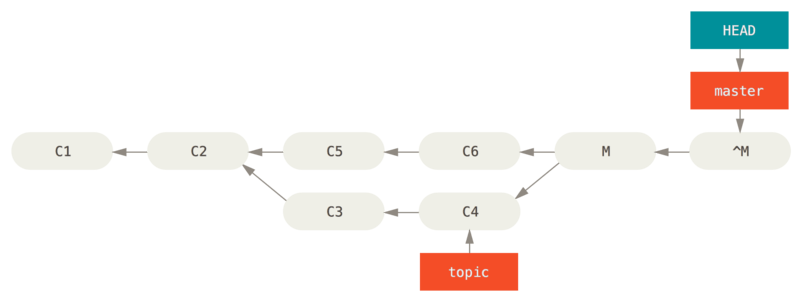
Figure 140. Historique après git revert -m 1
Le nouveau commit ^M a exactement le même contenu que C6, et
partant de là, c’est comme si la fusion n’avait pas eu lieu, mis à part
que les commits qui ne sont plus fusionnés sont toujours dans
l’historique de HEAD. Git sera confus si vous tentez de re-fusionner
topic dans master :
$ git merge topic
Already up-to-date.
Il n’y a rien dans topic qui ne soit pas déjà joignable depuis
master. Pire encore, si vous ajoutez du travail à topic et
re-fusionnez, Git n’ajoutera que les modifications depuis la fusion
inversée :
Figure 141. Historique avec une mauvaise fusion
Le meilleur contournement de ceci est de dé-inverser la fusion originale, puisque vous voulez ajouter les modifications qui ont été annulées, puis de créer un nouveau commit de fusion :
$ git revert ^M
[master 09f0126] Revert "Revert "Merge branch 'topic'""
$ git merge topic
Figure 142. Historique après re-fusion de la fusion annulée
Dans cet exemple, M et ^M s’annulent. ^^M fusionne effectivement
les modifications depuis C3 et C4, et C8 fusionne les
modifications depuis C7, donc à présent, topic est totalement
fusionnée.
Autres types de fusions
Jusqu’ici, nous avons traité les fusions normales entre deux branches qui ont été gérées normalement avec ce qui s’appelle la stratégie « récursive » de fusion. Il existe cependant d’autres manières de fusionner des branches. Traitons en quelques unes rapidement.
Préférence our ou theirs
Premièrement, il existe un autre mode utile que nous pouvons utiliser
avec le mode « recursive » normal de fusion. Nous avons déjà vu les
options ignore-all-space et ignore-space-change qui sont passées
avec -X mais nous pouvons aussi indiquer à Git de favoriser un côté
plutôt que l’autre lorsqu’il rencontre un conflit.
Par défaut, quand Git rencontre un conflit entre deux branches en cours
de fusion, il va ajouter des marqueurs de conflit de fusion dans le code
et marquer le fichier en conflit pour vous laisser le résoudre. Si vous
préférez que Git choisisse simplement un côté spécifique et qu’il ignore
l’autre côté au lieu de vous laisser fusionner manuellement le conflit,
vous pouvez passer -Xours ou -Xtheirs à la commande merge.
Si une des options est spécifiée, Git ne va pas ajouter de marqueurs de conflit. Toutes les différences qui peuvent être fusionnées seront fusionnées. Pour toutes les différences qui génèrent un conflit, Git choisira simplement la version du côté que vous avez spécifié, y compris pour les fichiers binaires.
Si nous retournons à l’exemple « hello world » précédent, nous pouvons voir que la fusion provoque des conflits.
$ git merge mundo
Fusion automatique de hello.rb
CONFLIT (contenu): Conflit de fusion dans hello.rb
La fusion automatique a échoué ; réglez les conflits et validez le résultat.
Cependant, si nous la lançons avec -Xours ou -Xtheirs, elle n’en
provoque pas.
$ git merge -Xours mundo
Fusion automatique de hello.rb
Merge made by the 'recursive' strategy.
hello.rb | 2 +-
test.sh | 2 ++
2 files changed, 3 insertions(+), 1 deletion(-)
create mode 100644 test.sh
Dans ce dernier cas, au lieu d’obtenir des marqueurs de conflit dans le fichier avec « hello mundo » d’un côté et « hola world » de l’autre, Git choisira simplement « hola world ». À part cela, toutes les autres modifications qui ne génèrent pas de conflit sont fusionnées sans problème.
Cette option peut aussi être passée à la commande git merge-file que
nous avons utilisée plus tôt en lançant quelque chose comme
git merge-file --ours pour les fusions de fichiers individuels.
Si vous voulez faire quelque chose similaire mais indiquer à Git de ne même pas essayer de fusionner les modifications de l’autre côté, il existe une option draconienne qui s’appelle la stratégie de fusion « ours ».
Cela réalisera une fusion factice. Cela enregistrera un nouveau commit de fusion avec les deux branches comme parents, mais ne regardera même pas la branche en cours de fusion. Cela enregistrera simplement le code exact de la branche courante comme résultat de la fusion.
$ git merge -s ours mundo
Merge made by the 'ours' strategy.
$ git diff HEAD HEAD~
$
Vous pouvez voir qu’il n’y a pas de différence entre la branche sur laquelle nous étions précédemment et le résultat de la fusion.
Cela peut s’avérer utile pour faire croire à Git qu’une branche est déjà
fusionnée quand on fusionne plus tard. Par exemple, disons que vous avez
créé une branche depuis une branche « release » et avez travaillé dessus
et que vous allez vouloir réintégrer ce travail dans master. Dans
l’intervalle, les correctifs de master doivent être reportés dans la
branche release. Vous pouvez fusionner la branche de correctif dans la
branche release et aussi faire un merge -s ours de cette branche
dans la branche master (même si le correctif est déjà présent) de
sorte que lorsque fusionnerez plus tard la branche release , il n’y
aura pas de conflit dû au correctif.
Subtree Merging
L’idée de la fusion de sous-arbre est que vous avez deux projets, et l’un des projets se réfère à un sous-dossier de l’autre et vice-versa. Quand vous spécifiez une fusion de sous-arbre, Git est souvent assez malin pour se rendre compte que l’un est un sous-arbre de l’autre et fusionner comme il faut.
Nous allons explorer à travers un exemple comment ajouter un projet séparé à l’intérieur d’un projet existant et ensuite fusionner le code du second dans un sous-dossier du premier.
D’abord, nous ajouterons l’application Rack à notre projet. Nous ajouterons le projet Rack en tant que référence distante dans notre propre projet puis l’extrairons dans sa propre branche :
$ git remote add rack_remote https://github.com/rack/rack
$ git fetch rack_remote
warning: no common commits
remote: Counting objects: 3184, done.
remote: Compressing objects: 100% (1465/1465), done.
remote: Total 3184 (delta 1952), reused 2770 (delta 1675)
Receiving objects: 100% (3184/3184), 677.42 KiB | 4 KiB/s, done.
Resolving deltas: 100% (1952/1952), done.
From https://github.com/rack/rack
* [new branch] build -> rack_remote/build
* [new branch] master -> rack_remote/master
* [new branch] rack-0.4 -> rack_remote/rack-0.4
* [new branch] rack-0.9 -> rack_remote/rack-0.9
$ git checkout -b rack_branch rack_remote/master
Branch rack_branch set up to track remote branch refs/remotes/rack_remote/master.
Switched to a new branch "rack_branch"
Maintenant nous avons la racine du projet Rack dans notre branche
rack_branch et notre propre projet dans la branche master. Si vous
extrayez un projet puis l’autre, vous verrez qu’ils ont des racines de
projet différentes :
$ ls
AUTHORS KNOWN-ISSUES Rakefile contrib lib
COPYING README bin example test
$ git checkout master
Switched to branch "master"
$ ls
README
C’est un concept assez étrange. Toutes les branches de votre dépôt n’ont pas vraiment besoin d’être des branches du même projet. C’est inhabituel, parce que c’est rarement utile, mais c’est assez facile d’avoir des branches qui contiennent des historiques totalement différents.
Dans notre cas, nous voulons tirer le projet Rack dans notre projet
master en tant que sous-dossier. Nous pouvons faire cela dans Git avec
la commande git read-tree. Vous en apprendrez plus sur read-tree et
ses amis dans Les tripes de Git, mais pour
l’instant sachez qu’elle lit l’arborescence d’une branche dans votre
index courant et dans le répertoire de travail. Nous venons de
rebasculer dans notre branche master, et nous tirons la branche
rack_branch dans le sous-dossier rack de notre branche master de
notre projet principal :
$ git read-tree --prefix=rack/ -u rack_branch
Quand nous validons, c’est comme si nous avions tous les fichiers Rack dans ce sous-dossier – comme si les avions copiés depuis une archive. Ce qui est intéressant est que nous pouvons assez facilement fusionner les modifications d’une des branches dans l’autre. Donc, si le projet Rack est mis à jour, nous pouvons tirer en amont les modifications en basculant sur cette branche et en tirant :
$ git checkout rack_branch
$ git pull
Ensuite, nous pouvons fusionner les modifications dans notre brancher
master. Nous pouvons utiliser git merge -s subtree et cela marchera
bien, mais Git fusionnera lui aussi les historiques ensemble, ce que
nous ne voudrons probablement pas. Pour tirer les modifications et
préremplir le message de validation, utilisez les options --squash et
--no-commit en complément de l’option de stratégie -s subtree :
$ git checkout master
$ git merge --squash -s subtree --no-commit rack_branch
Squash commit -- not updating HEAD
Automatic merge went well; stopped before committing as requested
Toutes les modifications du projet Rach sont fusionnées et prêtes à être
validées localement. Vous pouvez aussi faire l’inverse – faire les
modifications dans le sous-dossier rack de votre branche master et
ensuite les fusionner plus tard dans votre branche rack_branch pour
les soumettre aux mainteneurs ou les pousser en amont.
Ceci nous donne un moyen d’avoir un flux de travail quelque peu similaire au flux de travail des sous-modules sans utiliser les sous-modules (que nous couvrirons dans Sous-modules). Nous pouvons garder dans notre dépôt des branches avec d’autres projets liés et les fusionner façon sous-arbre dans notre projet occasionnellement. C’est bien par certains côtés ; par exemple tout le code est validé à un seul endroit. Cependant, cela a d’autres défauts comme le fait que c’est un petit peu plus complexe et c’est plus facile de faire des erreurs en réintégrant les modifications ou en poussant accidentellement une branche dans un dépôt qui n’a rien à voir.
Une autre chose un peu étrange est que pour obtenir la différence entre
ce que vous avez dans votre sous-dossier rack et le code dans votre
branche rack_branch – pour voir si vous avez besoin de les fusionner –
vous ne pouvez pas utiliser la commande diff classique. À la place,
vous devez lancer git diff-tree avec la branche que vous voulez
comparer :
$ git diff-tree -p rack_branch
Ou, pour comparer ce qui est dans votre sous-dossier rack avec ce
qu’était la branche master sur le serveur la dernière fois que vous
avez tiré, vous pouvez lancer
$ git diff-tree -p rack_remote/master
Rerere
La fonctionalité git rerere est une fonction un peu cachée. Le nom
vient de l’anglais reuse recorded resolution (« ré utiliser les ré
solutions en re gistrées ») et comme son nom l’indique, cela permet de
demander à Git de se souvenir comment vous avez résolu un conflit sur
une section de diff de manière que la prochaine fois qu’il rencontre le
même conflit, il le résolve automatiquement pour vous.
Il existe pas mal de scénarios pour lesquels cette fonctionalité peut se
montrer efficace. Un exemple mentionné dans la documentation cite le cas
d’une branche au long cours qui finira par fusionner proprement mais ne
souhaite pas montrer des fusions intermédiaires. Avec rerere activé,
vous pouvez fusionner de temps en temps, résoudre les conflits, puis
sauvegarder la fusion. Si vous faites ceci en continu, alors la dernière
fusion devrait être assez facile parce que rerere peut quasiment tout
faire automatiquement pour vous.
La même tactique peut être utilisée si vous souhaitez rebaser plusieurs fois une branche tout en ne souhaitant pas avoir à gérer les mêmes conflits de rebasage à chaque fois. Ou si vous voulez prendre la branche que vous avez fusionnée et si vous avez eu à corriger des conflits, puis décidez de la rebaser pour finir - vous souhaitez sûrement ne pas avoir à recorriger les mêmes conflits.
Une autre situation similaire apparaît quand vous fusionnez ensemble de temps en temps une série de branches thématiques évolutives dans un sommet testable, comme le projet Git lui-même le fait souvent. Si les tests échouent, vous pouvez rembobiner vos fusions et les rejouer en écartant la branche qui a provoqué l’erreur sans devoir résoudre à nouveau tous les conflits.
Pour activer la fonctionnalité rerere, vous devez simplement lancer le
paramétrage :
$ git config --global rerere.enabled true
Vous pouvez aussi l’activer en créant le répertoire .git/rr-cache dans
un dépôt spécifique, mais l’activation par ligne de commande reste plus
claire et permet d’activer la fonction globalement.
Voyons maintenant un exemple similaire au précédent. Supposons que nous avons un fichier qui contient ceci :
#! /usr/bin/env ruby
def hello
puts 'hello world'
end
Dans une branche, nous changeons « hello » en « hola », puis dans une autre branche nous changeons « world » en « mundo », comme précédemment.
Quand nous fusionnons les deux branches ensemble, nous obtenons un conflit de fusion :
$ git merge i18n-world
Fusion automatique de hello.rb
CONFLIT (contenu): Conflit de fusion dans hello.rb
Recorded preimage for 'hello.rb'
La fusion automatique a échoué ; réglez les conflits et validez le résultat.
Vous devriez avoir noté la présence d’un nouvelle ligne
Recorded preimage for FILE (« Enregistrement de la pré-image pour
FICHIER »). À part ce détail, cela ressemble à un conflit de fusion tout
à fait normal. À ce stade, rerere peut déjà nous dire un certain
nombre de choses. Normalement, vous lanceriez un git status pour voir
l’état actuel des conflits.
$ git status
# On branch master
# Unmerged paths:
# (use "git reset HEAD <file>..." to unstage)
# (use "git add <file>..." to mark resolution)
#
# both modified: hello.rb
#
Cependant, git rerere vous indiquera aussi les conflits pour lesquels
il a enregistré la pré-image grâce à git rerere status :
$ git rerere status
hello.rb
Et git rerere diff montrera l’état actuel de la résolution ‑ quel
était le conflit de départ et comment vous l’avez résolu.
$ git rerere diff
--- a/hello.rb
+++ b/hello.rb
@@ -1,11 +1,11 @@
#! /usr/bin/env ruby
def hello
-<<<<<<<
- puts 'hello mundo'
-=======
+<<<<<<< HEAD
puts 'hola world'
->>>>>>>
+=======
+ puts 'hello mundo'
+>>>>>>> i18n-world
end
En complément (et bien que ça n’ait pas vraiment à voir avec rerere),
vous pouvez utiliser ls-files -u pour voir les fichiers en conflit
ainsi que les versions précédentes, à droite et à gauche :
$ git ls-files -u
100644 39804c942a9c1f2c03dc7c5ebcd7f3e3a6b97519 1 hello.rb
100644 a440db6e8d1fd76ad438a49025a9ad9ce746f581 2 hello.rb
100644 54336ba847c3758ab604876419607e9443848474 3 hello.rb
Maintenant, vous pouvez le résoudre pour que la ligne de code soit
simplement puts 'hola mundo' et vous pouvez relancer la commande
rerere diff pour visualiser ce que rerere va mémoriser :
$ git rerere diff
--- a/hello.rb
+++ b/hello.rb
@@ -1,11 +1,7 @@
#! /usr/bin/env ruby
def hello
-<<<<<<<
- puts 'hello mundo'
-=======
- puts 'hola world'
->>>>>>>
+ puts 'hola mundo'
end
Cela indique simplement que quand Git voit un conflit de section dans un
fichier hello.rb qui contient « hello mundo » d’un côté et « hola
world » de l’autre, il doit résoudre ce conflit en « hola mundo ».
Maintenant, nous pouvons le marquer comme résolu et le valider :
$ git add hello.rb
$ git commit
Recorded resolution for 'hello.rb'.
[master 68e16e5] Merge branch 'i18n'
Vous pouvez voir qu’il a « enregistré la résolution pour FICHIER » (Recorded resolution for FILE).
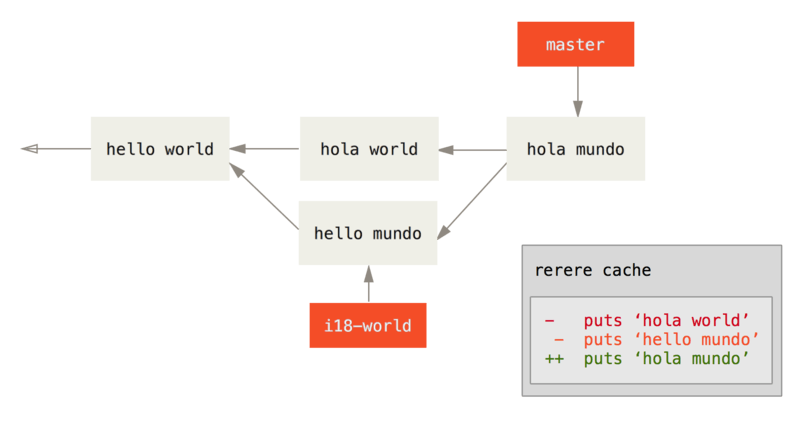
Maintenant, défaisons la fusion et rebasons plutôt la branche sur la
branche master. Nous pouvons déplacer notre branche en arrière en
utilisant reset comme vu dans Reset démystifié.
$ git reset --hard HEAD^
HEAD is now at ad63f15 i18n the hello
Notre fusion est défaite. Rebasons notre branche thématique.
$ git checkout i18n-world
Basculement sur la branche 'i18n-world'
$ git rebase master
Premièrement, rembobinons head pour rejouer votre travail par-dessus...
Application : i18n world
Utilisation de l'information de l'index pour reconstruire un arbre de base...
M hello.rb
Retour à un patch de la base et fusion à 3 points...
Fusion automatique de hello.rb
CONFLIT (contenu) : Conflit de fusion dans hello.rb
Resolved 'hello.rb' using previous resolution.
Échec d'intégration des modifications.
Le patch a échoué à 0001 i18n world
Ici, nous avons obtenu le conflit de fusion auquel nous nous attendions,
mais des lignes supplémentaires sont apparues, en particulier
Resolved FILE using previous resolution (FICHIER résolu en utilisant
une résolution précédente). Si nous inspectons le fichier hello.rb, il
ne contient pas de marqueur de conflit.
$ cat hello.rb
#! /usr/bin/env ruby
def hello
puts 'hola mundo'
end
git diff nous montrera comment le conflit a été re-résolu
automatiquement :
$ git diff
diff --cc hello.rb
index a440db6,54336ba..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,7 @@@
#! /usr/bin/env ruby
def hello
- puts 'hola world'
- puts 'hello mundo'
++ puts 'hola mundo'
end
Vous pouvez aussi recréer l’état de conflit du fichier avec la commande
checkout :
$ git checkout --conflict=merge hello.rb
$ cat hello.rb
#! /usr/bin/env ruby
def hello
<<<<<<< ours
puts 'hola world'
======
puts 'hello mundo'
>>>>>>> theirs
end
Nous avons vu un exemple de ceci dans Fusion
avancée. Pour le moment, re-résolvons-le en
relançant rerere :
$ git rerere
Resolved 'hello.rb' using previous resolution.
$ cat hello.rb
#! /usr/bin/env ruby
def hello
puts 'hola mundo'
end
Nous avons re-résolu le conflit du fichier automatiquement en utilisant
la résolution mémorisée par rerere. Vous pouvez le valider avec add
et terminer de rebaser.
$ git add hello.rb
$ git rebase --continue
Application: i18n one word
Dans les cas où vous souhaitez réaliser de nombreuses fusions
successives d’une branche thématique ou si vous souhaitez la
synchroniser souvent avec master sans devoir gérer des tas de conflits
de fusion, ou encore si vous rebasez souvent, vous pouvez activer
rerere qui vous simplifiera la vie.
Déboguer avec Git
Git fournit aussi quelques outils pour vous aider à déboguer votre projet. Puisque Git est conçu pour fonctionner avec pratiquement tout type de projet, ces outils sont plutôt génériques, mais ils peuvent souvent vous aider à traquer un bogue ou au moins cerner où cela tourne mal.
Fichier annoté
Si vous traquez un bogue dans votre code et que vous voulez savoir quand
il est apparu et pourquoi, annoter les fichiers est souvent le meilleur
moyen. Cela vous montre la dernière validation qui a modifié chaque
ligne de votre fichier. Donc, si vous voyez une méthode dans votre code
qui est boguée, vous pouvez visualiser le fichier annoté avec
git blame pour voir quand chaque ligne de la méthode a été modifiée
pour la dernière fois et par qui. Cet exemple utilise l’option -L pour
limiter la sortie des lignes 12 à 22 :
$ git blame -L 12,22 simplegit.rb
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 12) def show(tree = 'master')
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 13) command("git show #{tree}")
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 14) end
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 15)
9f6560e4 (Scott Chacon 2008-03-17 21:52:20 -0700 16) def log(tree = 'master')
79eaf55d (Scott Chacon 2008-04-06 10:15:08 -0700 17) command("git log #{tree}")
9f6560e4 (Scott Chacon 2008-03-17 21:52:20 -0700 18) end
9f6560e4 (Scott Chacon 2008-03-17 21:52:20 -0700 19)
42cf2861 (Magnus Chacon 2008-04-13 10:45:01 -0700 20) def blame(path)
42cf2861 (Magnus Chacon 2008-04-13 10:45:01 -0700 21) command("git blame #{path}")
42cf2861 (Magnus Chacon 2008-04-13 10:45:01 -0700 22) end
Remarquez que le premier champ est le SHA-1 partiel du dernier commit
à avoir modifié la ligne. Les deux champs suivants sont des valeurs
extraites du commit : l’auteur et la date du commit, vous pouvez
donc facilement voir qui a modifié la ligne et quand. Ensuite arrive le
numéro de ligne et son contenu. Remarquez également les lignes dont le
commit est ^4832fe2, elles désignent les lignes qui étaient dans la
version du fichier lors du premier commit de ce fichier. Ce commit
contient le premier ajout de ce fichier, et ces lignes n’ont pas été
modifiées depuis. Tout ça est un peu confus, parce que vous connaissez
maintenant au moins trois façons différentes que Git interprète ^ pour
modifier l’empreinte SHA, mais au moins, vous savez ce qu’il signifie
ici.
Une autre chose sympa sur Git, c’est qu’il ne suit pas explicitement les
renommages de fichier. Il enregistre les contenus puis essaye de deviner
ce qui a été renommé implicitement, après coup. Ce qui nous permet
d’utiliser cette fonctionnalité intéressante pour suivre toutes sortes
de mouvements de code. Si vous passez -C à git blame, Git analyse le
fichier que vous voulez annoter et essaye de deviner d’où les bouts de
code proviennent par copie ou déplacement. Récemment, j’ai remanié un
fichier nommé GITServerHandler.m en le divisant en plusieurs fichiers,
dont le fichier GITPackUpload.m. En annotant GITPackUpload.m avec
l’option -C, je peux voir quelles sections de code en sont
originaires :
$ git blame -C -L 141,153 GITPackUpload.m
f344f58d GITServerHandler.m (Scott 2009-01-04 141)
f344f58d GITServerHandler.m (Scott 2009-01-04 142) - (void) gatherObjectShasFromC
f344f58d GITServerHandler.m (Scott 2009-01-04 143) {
70befddd GITServerHandler.m (Scott 2009-03-22 144) //NSLog(@"GATHER COMMI
ad11ac80 GITPackUpload.m (Scott 2009-03-24 145)
ad11ac80 GITPackUpload.m (Scott 2009-03-24 146) NSString *parentSha;
ad11ac80 GITPackUpload.m (Scott 2009-03-24 147) GITCommit *commit = [g
ad11ac80 GITPackUpload.m (Scott 2009-03-24 148)
ad11ac80 GITPackUpload.m (Scott 2009-03-24 149) //NSLog(@"GATHER COMMI
ad11ac80 GITPackUpload.m (Scott 2009-03-24 150)
56ef2caf GITServerHandler.m (Scott 2009-01-05 151) if(commit) {
56ef2caf GITServerHandler.m (Scott 2009-01-05 152) [refDict setOb
56ef2caf GITServerHandler.m (Scott 2009-01-05 153)
C’est vraiment utile, non ? Normalement, vous obtenez comme commit originel celui dont votre code a été copié, puisque ce fut la première fois que vous avez touché à ces lignes dans ce fichier. Git vous montre le commit d’origine, celui où vous avez écrit ces lignes, même si c’était dans un autre fichier.
Recherche dichotomique
Annoter un fichier peut aider si vous savez déjà où le problème se
situe. Si vous ne savez pas ce qui a cassé le code, il peut y avoir des
dizaines, voire des centaines de commits depuis le dernier état où
votre code fonctionnait et vous aimeriez certainement exécuter
git bisect pour vous aider. La commande bisect effectue une
recherche par dichotomie dans votre historique pour vous aider à
identifier aussi vite que possible quel commit a vu le bogue naître.
Disons que vous venez juste de pousser une version finale de votre code
en production, vous récupérez un rapport de bogue à propos de quelque
chose qui n’arrivait pas dans votre environnement de développement, et
vous n’arrivez pas à trouver pourquoi votre code le fait. Vous retournez
sur votre code et il apparaît que vous pouvez reproduire le bogue mais
vous ne savez pas ce qui se passe mal. Vous pouvez faire une recherche
par dichotomie pour trouver ce qui ne va pas. D’abord, exécutez
git bisect start pour démarrer la procédure, puis utilisez la commande
git bisect bad pour dire que le commit courant est bogué. Ensuite,
dites à bisect quand le code fonctionnait, en utilisant
git bisect good [bonne_version] :
$ git bisect start
$ git bisect bad
$ git bisect good v1.0
Bisecting: 6 revisions left to test after this
[ecb6e1bc347ccecc5f9350d878ce677feb13d3b2] error handling on repo
Git trouve qu’il y a environ 12 commits entre celui que vous avez
marqué comme le dernier bon connu (v1.0) et la version courante qui
n’est pas bonne, et il a récupéré le commit du milieu à votre place. À
ce moment, vous pouvez dérouler vos tests pour voir si le bogue existait
dans ce commit. Si c’est le cas, il a été introduit quelque part avant
ce commit médian, sinon, il l’a été évidemment après. Il apparait que
le bogue ne se reproduit pas ici, vous le dites à Git en tapant
git bisect good et continuez votre périple :
$ git bisect good
Bisecting: 3 revisions left to test after this
[b047b02ea83310a70fd603dc8cd7a6cd13d15c04] secure this thing
Vous êtes maintenant sur un autre commit, à mi-chemin entre celui que
vous venez de tester et votre commit bogué. Vous exécutez une nouvelle
fois votre test et trouvez que ce commit est bogué, vous le dites à
Git avec git bisect bad :
$ git bisect bad
Bisecting: 1 revisions left to test after this
[f71ce38690acf49c1f3c9bea38e09d82a5ce6014] drop exceptions table
Ce commit-ci est bon, et Git a maintenant toutes les informations dont il a besoin pour déterminer où le bogue a été créé. Il vous affiche le SHA-1 du premier commit bogué, quelques informations du commit et quels fichiers ont été modifiés dans celui-ci, vous pouvez donc trouver ce qui s’est passé pour créer ce bogue :
$ git bisect good
b047b02ea83310a70fd603dc8cd7a6cd13d15c04 is first bad commit
commit b047b02ea83310a70fd603dc8cd7a6cd13d15c04
Author: PJ Hyett <pjhyett@example.com>
Date: Tue Jan 27 14:48:32 2009 -0800
secure this thing
:040000 040000 40ee3e7821b895e52c1695092db9bdc4c61d1730
f24d3c6ebcfc639b1a3814550e62d60b8e68a8e4 M config
Lorsque vous avez fini, vous devez exécuter git bisect reset pour
réinitialiser votre HEAD où vous étiez avant de commencer, ou vous
travaillerez dans un répertoire de travail non clairement défini :
$ git bisect reset
C’est un outil puissant qui vous aidera à vérifier des centaines de
commits en quelques minutes. En plus, si vous avez un script qui sort
avec une valeur 0 s’il est bon et autre chose sinon, vous pouvez même
automatiser git bisect. Premièrement vous lui spécifiez l’intervalle
en lui fournissant les bon et mauvais commits connus. Vous pouvez
faire cela en une ligne en les entrant à la suite de la commande
bisect start, le mauvais commit d’abord :
$ git bisect start HEAD v1.0
$ git bisect run test-error.sh
Cela exécute automatiquement test-error.sh sur chaque commit jusqu’à
ce que Git trouve le premier commit bogué. Vous pouvez également
exécuter des commandes comme make ou make tests ou quoi que ce soit
qui exécute des tests automatisés à votre place.
Sous-modules
Il arrive souvent lorsque vous travaillez sur un projet que vous deviez utiliser un autre projet comme dépendance. Cela peut être une bibliothèque qui est développée par une autre équipe ou que vous développez séparément pour l’utiliser dans plusieurs projets parents. Ce scénario provoque un problème habituel : vous voulez être capable de gérer deux projets séparés tout en utilisant l’un dans l’autre.
Voici un exemple. Supposons que vous développez un site web et que vous créez des flux Atom. Plutôt que d’écrire votre propre code de génération Atom, vous décidez d’utiliser une bibliothèque. Vous allez vraisemblablement devoir soit inclure ce code depuis un gestionnaire partagé comme CPAN ou Ruby gem, soit copier le code source dans votre propre arborescence de projet. Le problème d’inclure la bibliothèque en tant que bibliothèque externe est qu’il est difficile de la personnaliser de quelque manière que ce soit et encore plus de la déployer, car vous devez vous assurer de la disponibilité de la bibliothèque chez chaque client. Mais le problème d’inclure le code dans votre propre projet est que n’importe quelle personnalisation que vous faites est difficile à fusionner lorsque les modifications du développement principal arrivent.
Git gère ce problème avec les sous-modules. Les sous-modules vous permettent de gérer un dépôt Git comme un sous-répertoire d’un autre dépôt Git. Cela vous laisse la possibilité de cloner un dépôt dans votre projet et de garder isolés les commits de ce dépôt.
Démarrer un sous-module
Détaillons le développement d’un projet simple qui a été divisé en un projet principal et quelques sous-projets.
Commençons par ajouter le dépôt d’un projet Git existant comme
sous-module d’un dépôt sur lequel nous travaillons. Pour ajouter un
nouveau sous-module, nous utilisons la commande git submodule add avec
l’URL du projet que nous souhaitons suivre. Dans cette exemple, nous
ajoutons une bibliothèque nommée « DbConnector ».
$ git submodule add https://github.com/chaconinc/DbConnector
Clonage dans 'DbConnector'...
remote: Counting objects: 11, done.
remote: Compressing objects: 100% (10/10), done.
remote: Total 11 (delta 0), reused 11 (delta 0)
Dépaquetage des objets: 100% (11/11), fait.
Vérification de la connectivité... fait.
Par défaut, les sous-modules ajoutent le sous-projet dans un répertoire portant le même nom que le dépôt, dans notre cas « DbConnector ». Vous pouvez ajouter un chemin différent à la fin de la commande si vous souhaitez le placer ailleurs.
Si vous lancez git status à ce moment, vous noterez quelques
différences.
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui seront validées :
(utilisez "git reset <fichier>..." pour désindexer)
nouveau fichier : .gitmodules
nouveau fichier : DbConnector
Premièrement, un fichier .gitmodules vient d’apparaître. C’est le
fichier de configuration qui stocke la liaison entre l’URL du projet et
le sous-répertoire local dans lequel vous l’avez tiré.
$ cat .gitmodules
[submodule "DbConnector"]
path = DbConnector
url = https://github.com/chaconinc/DbConnector
Si vous avez plusieurs sous-modules, vous aurez plusieurs entrées dans
ce fichier. Il est important de noter que ce fichier est en gestion de
version comme vos autres fichiers, à l’instar de votre fichier
.gitignore. Il est poussé et tiré comme le reste de votre projet.
C’est également le moyen que les autres personnes qui clonent votre
projet ont de savoir où récupérer le projet du sous-module.
Comme l’URL dans le fichier |
L’autre information dans la sortie de git status est l’entrée du
répertoire du projet. Si vous exécutez git diff, vous verrez quelque
chose d’intéressant :
$ git diff --cached DbConnector
diff --git a/DbConnector b/DbConnector
new file mode 160000
index 0000000..c3f01dc
--- /dev/null
+++ b/DbConnector
@@ -0,0 +1 @@
+Subproject commit c3f01dc8862123d317dd46284b05b6892c7b29bc
Même si DbConnector est un sous-répertoire de votre répertoire de
travail, Git le voit comme un sous-module et ne suit pas son contenu (si
vous n’êtes pas dans ce répertoire). En échange, Git l’enregistre comme
un commit particulier de ce dépôt.
Si vous souhaitez une sortie diff plus agréable, vous pouvez passer
l’option --submodule à git diff.
$ git diff --cached --submodule
diff --git a/.gitmodules b/.gitmodules
new file mode 100644
index 0000000..71fc376
--- /dev/null
+++ b/.gitmodules
@@ -0,0 +1,3 @@
+[submodule "DbConnector"]
+ path = DbConnector
+ url = https://github.com/chaconinc/DbConnector
Submodule DbConnector 0000000...c3f01dc (new submodule)
Au moment de valider, vous voyez quelque chose comme :
$ git commit -am 'added DbConnector module'
[master fb9093c] added DbConnector module
2 files changed, 4 insertions(+)
create mode 100644 .gitmodules
create mode 160000 DbConnector
Remarquez le mode 160000 pour l’entrée DbConnector. C’est un mode
spécial de Git qui signifie globalement que vous êtes en train
d’enregistrer un commit comme un répertoire plutôt qu’un
sous-répertoire ou un fichier.
Cloner un projet avec des sous-modules
Maintenant, vous allez apprendre à cloner un projet contenant des sous-modules. Quand vous récupérez un tel projet, vous obtenez les différents répertoires qui contiennent les sous-modules, mais encore aucun des fichiers :
$ git clone https://github.com/chaconinc/MainProject
Clonage dans 'MainProject'...
remote: Counting objects: 14, done.
remote: Compressing objects: 100% (13/13), done.
remote: Total 14 (delta 1), reused 13 (delta 0)
Dépaquetage des objets: 100% (14/14), fait.
Vérification de la connectivité... fait.
$ cd MainProject
$ ls -la
total 16
drwxr-xr-x 9 schacon staff 306 Sep 17 15:21 .
drwxr-xr-x 7 schacon staff 238 Sep 17 15:21 ..
drwxr-xr-x 13 schacon staff 442 Sep 17 15:21 .git
-rw-r--r-- 1 schacon staff 92 Sep 17 15:21 .gitmodules
drwxr-xr-x 2 schacon staff 68 Sep 17 15:21 DbConnector
-rw-r--r-- 1 schacon staff 756 Sep 17 15:21 Makefile
drwxr-xr-x 3 schacon staff 102 Sep 17 15:21 includes
drwxr-xr-x 4 schacon staff 136 Sep 17 15:21 scripts
drwxr-xr-x 4 schacon staff 136 Sep 17 15:21 src
$ cd DbConnector/
$ ls
$
Le répertoire DbConnector est présent mais vide. Vous devez exécuter
deux commandes : git submodule init pour initialiser votre fichier
local de configuration, et git submodule update pour tirer toutes les
données de ce projet et récupérer le commit approprié tel que listé
dans votre super-projet :
$ git submodule init
Sous-module 'DbConnector' (https://github.com/chaconinc/DbConnector) enregistré pour le chemin 'DbConnector'
$ git submodule update
Clonage dans 'DbConnector'...
remote: Counting objects: 11, done.
remote: Compressing objects: 100% (10/10), done.
remote: Total 11 (delta 0), reused 11 (delta 0)
Unpacking objects: 100% (11/11), done.
Checking connectivity... done.
Submodule path 'DbConnector': checked out 'c3f01dc8862123d317dd46284b05b6892c7b29bc'
Votre répertoire DbConnector est maintenant dans l’état exact dans
lequel il était la dernière fois que vous avez validé.
Il existe une autre manière plus simple d’arriver au même résultat. Si
vous passez l’option --recurse-submodules à la commande git clone,
celle-ci initialisera et mettra à jour automatiquement chaque
sous-module du dépôt.
$ git clone --recurse-submodules https://github.com/chaconinc/MainProject
Clonage dans 'MainProject'...
remote: Counting objects: 14, done.
remote: Compressing objects: 100% (13/13), done.
remote: Total 14 (delta 1), reused 13 (delta 0)
Dépaquetage des objets: 100% (14/14), fait.
Vérification de la connectivité... fait.
Submodule 'DbConnector' (https://github.com/chaconinc/DbConnector) registered for path 'DbConnector'
Clonage dans 'DbConnector'...
remote: Counting objects: 11, done.
remote: Compressing objects: 100% (10/10), done.
remote: Total 11 (delta 0), reused 11 (delta 0)
Dépaquetage des objets: 100% (11/11), fait.
Vérification de la connectivité... fait.
chemin du sous-module 'DbConnector' : 'c3f01dc8862123d317dd46284b05b6892c7b29bc' extrait
Travailler sur un projet comprenant des sous-modules
Nous avons à présent une copie d’un projet comprenant des sous-modules, et nous allons collaborer à la fois sur le projet principal et sur le projet du sous-module.
Tirer des modifications amont
Le modèle le plus simple d’utilisation des sous-modules est le cas de la simple consommation d’un sous-projet duquel on souhaite obtenir les mises à jour de temps en temps mais auquel on n’apporte pas de modification dans la copie de travail. Examinons un exemple simple.
Quand vous souhaitez vérifier si le sous-module a évolué, vous pouvez
vous rendre dans le répertoire correspondant et lancer git fetch puis
git merge de la branche amont pour mettre à jour votre code local.
$ git fetch
From https://github.com/chaconinc/DbConnector
c3f01dc..d0354fc master -> origin/master
$ git merge origin/master
Mise à jour c3f01dc..d0354fc
Avance rapide
scripts/connect.sh | 1 +
src/db.c | 1 +
2 files changed, 2 insertions(+)
Si vous revenez maintenant dans le projet principal et lancez
git diff --submodule, vous pouvez remarquer que le sous-module a été
mis à jour et vous pouvez obtenir une liste des commits qui y ont été
ajoutés. Si vous ne voulez pas taper --submodule à chaque fois que
vous lancez git diff, vous pouvez le régler comme format par défaut en
positionnant le paramètre de configuration diff.submodule à la valeur
« log ».
$ git config --global diff.submodule log
$ git diff
Submodule DbConnector c3f01dc..d0354fc:
> more efficient db routine
> better connection routine
Si vous validez à ce moment, vous fixez la version du sous-module à la version actuelle quand d’autres personnes mettront à jour votre projet.
Il existe aussi un moyen plus facile, si vous préférez ne pas avoir à
récupérer et fusionner manuellement les modifications dans le
sous-répertoire. Si vous lancez la commande
git submodule update --remote, Git se rendra dans vos sous-modules et
réalisera automatiquement le fetch et le merge.
$ git submodule update --remote DbConnector
remote: Counting objects: 4, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 4 (delta 2), reused 4 (delta 2)
Dépaquetage des objets: 100% (4/4), fait.
Depuis https://github.com/chaconinc/DbConnector
3f19983..d0354fc master -> origin/master
chemin du sous-module 'DbConnector': checked out 'd0354fc054692d3906c85c3af05ddce39a1c0644' extrait
Cette commande considère par défaut que vous souhaitez mettre à jour la
copie locale vers la branche master du dépôt du sous-module. Vous
pouvez, cependant, indiquer une autre branche. Par exemple, si le
sous-module DbConnector suit la branche stable du dépôt amont, vous
pouvez l’indiquer soit dans votre fichier .gitmodules (pour que tout
le monde le suive de même) ou juste dans votre fichier local
.git/config. Voyons ceci dans le cas du fichier .gitmodules :
$ git config -f .gitmodules submodule.DbConnector.branch stable
$ git submodule update --remote
remote: Counting objects: 4, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 4 (delta 2), reused 4 (delta 2)
Dépaquetage des objets: 100% (4/4), fait.
Depuis https://github.com/chaconinc/DbConnector
27cf5d3..c87d55d stable -> origin/stable
chemin du sous-module 'DbConnector' : 'c87d55d4c6d4b05ee34fbc8cb6f7bf4585ae6687' extrait
Si vous ne spécifiez pas la partie -f .gitmodules, la commande ne fera
qu’une modification locale, mais il semble plus logique d’inclure cette
information dans l’historique du projet pour que tout le monde soit au
diapason.
Quand vous lancez git status, Git vous montrera que nous avons de
nouveaux commits (« new commits ») pour le sous-module.
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : .gitmodules
modifié : DbConnector (new commits)
aucune modification n'a été ajoutée à la validation (utilisez "git add" ou "git commit -a")
Si vous activez le paramètre de configuration status.submodulesummary,
Git vous montrera aussi un résumé des modifications dans vos
sous-modules :
$ git config status.submodulesummary 1
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git checkout -- <fichier>..." pour annuler les modifications dans la copie de travail)
modifié : .gitmodules
modifié : DbConnector (new commits)
Sous-modules modifiés mais non mis à jour :
* DbConnector c3f01dc...c87d55d (4):
> catch non-null terminated lines
Ici, si vous lancez git diff, vous pouvez voir que le fichier
.gitmodules a été modifié mais aussi qu’il y a un certain nombre de
commits qui ont été tirés et sont prêts à être validés dans le projet
du sous-module.
$ git diff
diff --git a/.gitmodules b/.gitmodules
index 6fc0b3d..fd1cc29 100644
--- a/.gitmodules
+++ b/.gitmodules
@@ -1,3 +1,4 @@
[submodule "DbConnector"]
path = DbConnector
url = https://github.com/chaconinc/DbConnector
+ branch = stable
Submodule DbConnector c3f01dc..c87d55d:
> catch non-null terminated lines
> more robust error handling
> more efficient db routine
> better connection routine
C’est une information intéressante car vous pouvez voir le journal des
modifications que vous vous apprêtez à valider dans votre sous-module.
Une fois validées, vous pouvez encore visualiser cette information en
lançant git log -p.
$ git log -p --submodule
commit 0a24cfc121a8a3c118e0105ae4ae4c00281cf7ae
Author: Scott Chacon <schacon@gmail.com>
Date: Wed Sep 17 16:37:02 2014 +0200
updating DbConnector for bug fixes
diff --git a/.gitmodules b/.gitmodules
index 6fc0b3d..fd1cc29 100644
--- a/.gitmodules
+++ b/.gitmodules
@@ -1,3 +1,4 @@
[submodule "DbConnector"]
path = DbConnector
url = https://github.com/chaconinc/DbConnector
+ branch = stable
Submodule DbConnector c3f01dc..c87d55d:
> catch non-null terminated lines
> more robust error handling
> more efficient db routine
> better connection routine
Par défaut, Git essaiera de mettre à jour tous les sous-modules lors
d’une commande git submodule update --remote, donc si vous avez de
nombreux sous-modules, il est préférable de spécifier le sous-module que
vous souhaitez mettre à jour.
Travailler sur un sous-module
Il y a fort à parier que si vous utilisez des sous-modules, vous le faites parce que vous souhaitez en réalité travailler sur le code du sous-module en même temps que sur celui du projet principal (ou à travers plusieurs sous-modules). Sinon, vous utiliseriez plutôt un outil de gestion de dépendances plus simple (tel que Maven ou Rubygems).
De ce fait, détaillons un exemple de modifications réalisées dans le sous-module en même temps que dans le projet principal et de validation et de publication des modifications dans le même temps.
Jusqu’à maintenant, quand nous avons lancé la commande
git submodule update pour récupérer les modifications depuis les
dépôts des sous-modules, Git récupérait les modifications et mettait les
fichiers locaux à jour mais en laissant le sous-répertoire dans un état
appelé « HEAD détachée ». Cela signifie qu’il n’y pas de branche locale
de travail (comme master, par exemple) pour y valider les
modifications. Donc, toutes les modifications que vous y faites ne sont
pas suivies non plus.
Pour rendre votre sous-module plus adapté à la modification, vous avez
besoin de deux choses. Vous devez vous rendre dans chaque sous-module et
extraire une branche de travail. Ensuite vous devez dire à Git ce qu’il
doit faire si vous avez réalisé des modifications et que vous lancez
git submodule update --remote pour tirer les modifications amont. Les
options disponibles sont soit de les fusionner dans votre travail local,
soit de tenter de rebaser le travail local par dessus les modifications
distantes.
En premier, rendons-nous dans le répertoire de notre sous-module et extrayons une branche.
$ git checkout stable
Basculement sur la branche 'stable'
Attaquons-nous au choix de politique de gestion. Pour le spécifier
manuellement, nous pouvons simplement ajouter l’option --merge à
l’appel de update. Nous voyons ici qu’une modification était
disponible sur le serveur pour ce sous-module et qu’elle a été
fusionnée.
$ git submodule update --remote --merge
remote: Counting objects: 4, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 4 (delta 2), reused 4 (delta 2)
Dépaquetage des objets: 100% (4/4), fait.
Depuis https://github.com/chaconinc/DbConnector
c87d55d..92c7337 stable -> origin/stable
Mise à jour de c87d55d..92c7337
Avance rapide
src/main.c | 1 +
1 file changed, 1 insertion(+)
chemin du sous-module 'DbConnector': fusionné dans '92c7337b30ef9e0893e758dac2459d07362ab5ea'
Si nous nous rendons dans le répertoire DbConnector, les nouvelles
modifications sont déjà fusionnées dans notre branche locale stable.
Voyons maintenant ce qui arrive si nous modifions localement la
bibliothèque et que quelqu’un pousse une autre modification en amont
dans le même temps.
$ cd DbConnector/
$ vim src/db.c
$ git commit -am 'unicode support'
[stable f906e16] unicode support
1 file changed, 1 insertion(+)
Maintenant, si nous mettons à jour notre sous-module, nous pouvons voir ce qui arrive lors d’un rebasage de deux modifications concurrentes.
$ git submodule update --remote --rebase
Premièrement, rembobinons head pour rejouer votre travail par-dessus...
Application : unicode support
chemin du sous-module 'DbConnector': rebasé dans '5d60ef9bbebf5a0c1c1050f242ceeb54ad58da94'
Si vous oubliez de spécifier --rebase ou --merge, Git mettra juste à
jour le sous-module vers ce qui est sur le serveur et réinitialisera
votre projet à l’état « HEAD détachée ».
$ git submodule update --remote
chemin du sous-module 'DbConnector' : '5d60ef9bbebf5a0c1c1050f242ceeb54ad58da94' extrait
Si cela arrive, ne vous inquiétez pas, vous pouvez simplement revenir
dans le répertoire et extraire votre branche (qui contiendra encore
votre travail) et fusionner ou rebaser origin/stable (ou la branche
distante que vous souhaitez) à la main.
Si vous n’avez pas validé vos modifications dans votre sous-module, et que vous lancez une mise à jour de sous-module qui causerait des erreurs, Git récupérera les modifications mais n’écrasera pas le travail non validé dans votre répertoire de sous-module.
$ git submodule update --remote
remote: Counting objects: 4, done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 4 (delta 0), reused 4 (delta 0)
Dépaquetage des objets: 100% (4/4), fait.
Depuis https://github.com/chaconinc/DbConnector
5d60ef9..c75e92a stable -> origin/stable
error: Vos modifications locales seraient écrasées par checkout:
scripts/setup.sh
Please, commit your changes or stash them before you can switch branches.
Aborting
Impossible d'extraire 'c75e92a2b3855c9e5b66f915308390d9db204aca' dans le chemin du sous-module 'DbConnector'
Si vous avez réalisé des modifications qui entrent en conflit avec des modifications amont, Git vous en informera quand vous mettrez à jour.
$ git submodule update --remote --merge
Auto-merging scripts/setup.sh
CONFLIT (contenu): Conflit de fusion dans scripts/setup.sh
La fusion automatique a échoué ; réglez les conflits et validez le résultat
Impossible de fusionner 'c75e92a2b3855c9e5b66f915308390d9db204aca' dans le chemin du sous-module 'DbConnector'
Vous pouvez vous rendre dans le répertoire du sous-module et résoudre le conflit normalement.
Publier les modifications dans un sous-module
Nous avons donc des modifications dans notre répertoire de sous-module, venant à la fois du dépôt amont et de modifications locales non publiées.
$ git diff
Submodule DbConnector c87d55d..82d2ad3:
> Merge from origin/stable
> updated setup script
> unicode support
> remove unnessesary method
> add new option for conn pooling
Si nous validons dans le projet principal et que nous le poussons en amont sans pousser les modifications des sous-modules, les autres personnes qui voudront essayer notre travail vont avoir de gros problèmes vu qu’elles n’auront aucun moyen de récupérer les modifications des sous-modules qui en font partie. Ces modifications n’existent que dans notre copie locale.
Pour être sur que cela n’arrive pas, vous pouvez demander à Git de
vérifier que tous vos sous-modules ont été correctement poussés avant de
pouvoir pousser le projet principal. La commande git push accepte un
argument --recurse-submodules qui peut avoir pour valeur « check »
ou « on-demand ». L’option « check » fera échouer push si au moins
une des modifications des sous-modules n’a pas été poussée.
$ git push --recurse-submodules=check
The following submodule paths contain changes that can
not be found on any remote:
DbConnector
Please try
git push --recurse-submodules=on-demand
or cd to the path and use
git push
to push them to a remote.
Comme vous pouvez le voir, il donne aussi quelques conseils utiles sur ce que nous pourrions vouloir faire ensuite. L’option simple consiste à se rendre dans chaque sous-module et à pousser manuellement sur les dépôts distants pour s’assurer qu’ils sont disponibles publiquement, puis de réessayer de pousser le projet principal.
L’autre option consiste à utiliser la valeur « on-demand » qui essaiera de faire tout ceci pour vous.
$ git push --recurse-submodules=on-demand
Pushing submodule 'DbConnector'
Décompte des objets: 9, fait.
Delta compression using up to 8 threads.
Compression des objets: 100% (8/8), fait.
Écriture des objets: 100% (9/9), 917 bytes | 0 bytes/s, fait.
Total 9 (delta 3), reused 0 (delta 0)
To https://github.com/chaconinc/DbConnector
c75e92a..82d2ad3 stable -> stable
Décompte des objets: 2, fait.
Delta compression using up to 8 threads.
Compression des objets: 100% (2/2), fait.
Écriture des objets: 100% (2/2), 266 bytes | 0 bytes/s, fait.
Total 2 (delta 1), reused 0 (delta 0)
To https://github.com/chaconinc/MainProject
3d6d338..9a377d1 master -> master
Comme vous pouvez le voir, Git s’est rendu dans le module DbConnector
et l’a poussé avant de pousser le projet principal. Si la poussée du
sous-module échoue pour une raison quelconque, la poussée du projet
principal sera annulée.
Fusion de modifications de sous-modules
Si vous changez la référence d’un sous-module en même temps qu’une autre personne, il se peut que cela pose problème. Particulièrement, si les historiques des sous-modules ont divergé et sont appliqués à des branches divergentes dans un super-projet, rapprocher toutes les modifications peut demander un peu de travail.
Si un des commits est un ancêtre direct d’un autre (c’est-à-dire une fusion en avance rapide), alors Git choisira simplement ce dernier pour la fusion et cela se résoudra tout seul. Cependant, Git ne tentera pas de fusion, même très simple, pour vous. Si les commits d’un sous-module divergent et doivent être fusionnés, vous obtiendrez quelque chose qui ressemble à ceci :
$ git pull
remote: Counting objects: 2, done.
remote: Compressing objects: 100% (1/1), done.
remote: Total 2 (delta 1), reused 2 (delta 1)
Dépaquetage des objets: 100% (2/2), fait.
From https://github.com/chaconinc/MainProject
9a377d1..eb974f8 master -> origin/master
Fetching submodule DbConnector
warning: Failed to merge submodule DbConnector (merge following commits not found)
Fusion automatique de DbConnector
CONFLIT (sous-module): Conflit de fusion dans DbConnector
La fusion automatique a échoué ; réglez les conflits et validez le résultat.
Donc, ce qui s’est passé en substance est que Git a découvert que les deux points de fusion des branches à fusionner dans l’historique du sous-module sont divergents et doivent être fusionnés. Il l’explique par « merge following commits not found » (fusion suivant les commits non trouvée), ce qui n’est pas clair mais que nous allons expliquer d’ici peu.
Pour résoudre le problème, vous devez comprendre l’état dans lequel le
sous-module devrait se trouver. Étrangement, Git ne vous donne pas
d’information utile dans ce cas, pas même les SHA-1 des commits des
deux côtés de l’historique. Heureusement, c’est assez facile à
comprendre. Si vous lancez git diff, vous pouvez obtenir les SHA-1 des
commits enregistrés dans chacune des branches que vous essayiez de
fusionner.
$ git diff
diff --cc DbConnector
index eb41d76,c771610..0000000
--- a/DbConnector
+++ b/DbConnector
Donc, dans ce cas, eb41d76 est le commit dans notre sous-module que
nous avions et c771610 est le commit amont. Si nous nous rendons
dans le répertoire du sous-module, il devrait déjà être sur eb41d76
parce que la fusion ne l’a pas touché. S’il n’y est pas, vous pouvez
simplement créer et extraire une branche qui pointe dessus.
Ce qui importe, c’est le SHA-1 du commit venant de l’autre branche. C’est ce que nous aurons à fusionner. Vous pouvez soit essayer de fusionner avec le SHA-1 directement ou vous pouvez créer une branche à partir du commit puis essayer de la fusionner. Nous suggérons d’utiliser cette dernière méthode, ne serait-ce que pour obtenir un message de fusion plus parlant.
Donc, rendons-nous dans le répertoire du sous-module, créons une branche
basée sur ce second SHA-1 obtenu avec git diff et fusionnons
manuellement.
$ cd DbConnector
$ git rev-parse HEAD
eb41d764bccf88be77aced643c13a7fa86714135
$ git branch try-merge c771610
(DbConnector) $ git merge try-merge
Fusion automatique de src/main.c
CONFLIT (contenu): Conflit de fusion dans src/main.c
La fusion automatique a échoué ; réglez les conflits et validez le résultat.
Nous avons eu un conflit de fusion ici, donc si nous le résolvons et validons, alors nous pouvons simplement mettre à jour le projet principal avec le résultat.
$ vim src/main.c (1)
$ git add src/main.c
$ git commit -am 'fusion de nos modifications'
[master 9fd905e] fusion de nos modifications
$ cd .. (2)
$ git diff (3)
diff --cc DbConnector
index eb41d76,c771610..0000000
--- a/DbConnector
+++ b/DbConnector
@@@ -1,1 -1,1 +1,1 @@@
- Subproject commit eb41d764bccf88be77aced643c13a7fa86714135
-Subproject commit c77161012afbbe1f58b5053316ead08f4b7e6d1d
++Subproject commit 9fd905e5d7f45a0d4cbc43d1ee550f16a30e825a
$ git add DbConnector (4)
$ git commit -m "Fusion du travail de Tom" (5)
[master 10d2c60] Fusion du travail de Tom
| 1 | Nous résolvons le conflit |
| 2 | Ensuite, nous retournons dans le projet principal |
| 3 | Nous pouvons revérifier les SHA-1 |
| 4 | Nous résolvons l’entrée en conflit dans le sous-module |
| 5 | Enfin, nous validons la résolution. |
Cela peut paraître compliqué mais ce n’est pas très difficile.
Curieusement, il existe un autre cas que Git gère seul. Si un commit de fusion existe dans le répertoire du sous-module qui contient les deux commits dans ses ancêtres, Git va le suggérer comme solution possible. Il voit qu’à un certain point de l’historique du projet du sous-module, quelqu’un a fusionné les branches contenant ces deux commits, donc vous désirerez peut-être utiliser celui-ci.
C’est pourquoi le message d’erreur précédent s’intitulait « merge following commits not found », parce que justement, il ne pouvait pas trouver le commit de fusion. C’est déroutant car qui s’attendrait à ce qu’il essaie de le chercher ?
S’il trouve un seul commit de fusion acceptable, vous verrez ceci :
$ git merge origin/master
warning: Failed to merge submodule DbConnector (not fast-forward)
Found a possible merge resolution for the submodule:
9fd905e5d7f45a0d4cbc43d1ee550f16a30e825a: > merged our changes
If this is correct simply add it to the index for example
by using:
git update-index --cacheinfo 160000 9fd905e5d7f45a0d4cbc43d1ee550f16a30e825a "DbConnector"
which will accept this suggestion.
Fusion automatique de DbConnector
CONFLIT (submodule): Conflit de fusion dans DbConnector
La fusion automatique a échoué ; réglez les conflits et validez le résultat.
Ce qu’il suggère de faire est de mettre à jour l’index comme si vous
aviez lancé git add, ce qui élimine le conflit, puis de valider. Vous
ne devriez cependant pas le faire. Vous pouvez plus simplement vous
rendre dans le répertoire du sous-module, visualiser la différence,
avancer en avance rapide sur le commit, le tester puis le valider.
$ cd DbConnector/
$ git merge 9fd905e
Mise à jour eb41d76..9fd905e
Avance rapide
$ cd ..
$ git add DbConnector
$ git commit -am 'Avance rapide sur un fils commun dans le sous-module'
Cela revient au même, mais de cette manière vous pouvez au moins vérifier que ça fonctionne et vous avez le code dans votre répertoire de sous-module quand c’est terminé.
Trucs et astuces pour les sous-modules
Il existe quelques commandes qui permettent de travailler plus facilement avec les sous-modules.
Submodule foreach
Il existe une commande submodule foreach qui permet de lancer une
commande arbitraire dans chaque sous-module. C’est particulièrement
utile si vous avez plusieurs sous-modules dans le même projet.
Par exemple, supposons que nous voulons développer une nouvelle fonctionnalité ou faire un correctif et que nous avons déjà du travail en cours dans plusieurs sous-modules. Nous pouvons facilement remiser tout le travail en cours dans tous les sous-modules.
$ git submodule foreach 'git stash'
Entering 'CryptoLibrary'
No local changes to save
Entering 'DbConnector'
Saved working directory and index state WIP on stable: 82d2ad3 Merge from origin/stable
HEAD is now at 82d2ad3 Merge from origin/stable
Ensuite, nous pouvons créer une nouvelle branche et y basculer dans tous nos sous-modules.
$ git submodule foreach 'git checkout -b featureA'
Entering 'CryptoLibrary'
Basculement sur la nouvelle branche 'featureA'
Entering 'DbConnector'
Basculement sur la nouvelle branche 'featureA'
Vous comprenez l’idée. Une commande vraiment utile permet de produire un joli diff unifié des modifications dans le projet principal ainsi que dans tous les sous-projets.
$ git diff; git submodule foreach 'git diff'
Submodule DbConnector contains modified content
diff --git a/src/main.c b/src/main.c
index 210f1ae..1f0acdc 100644
--- a/src/main.c
+++ b/src/main.c
@@ -245,6 +245,8 @@ static int handle_alias(int *argcp, const char ***argv)
commit_pager_choice();
+ url = url_decode(url_orig);
+
/* build alias_argv */
alias_argv = xmalloc(sizeof(*alias_argv) * (argc + 1));
alias_argv[0] = alias_string + 1;
Entering 'DbConnector'
diff --git a/src/db.c b/src/db.c
index 1aaefb6..5297645 100644
--- a/src/db.c
+++ b/src/db.c
@@ -93,6 +93,11 @@ char *url_decode_mem(const char *url, int len)
return url_decode_internal(&url, len, NULL, &out, 0);
}
+char *url_decode(const char *url)
+{
+ return url_decode_mem(url, strlen(url));
+}
+
char *url_decode_parameter_name(const char **query)
{
struct strbuf out = STRBUF_INIT;
Ici, nous pouvons voir que nous définissons une fonction dans un sous-module et que nous l’appelons dans le projet principal. C’est un exemple exagérément simplifié, mais qui aide à mieux comprendre l’utilité de cette commande.
Alias utiles
Vous pourriez être intéressé de définir quelques alias pour des commandes longues pour lesquelles vous ne pouvez pas régler la configuration par défaut. Nous avons traité la définition d’alias Git dans Les alias Git, mais voici un exemple d’alias que vous pourriez trouver utiles si vous voulez travailler sérieusement avec les sous-modules de Git.
$ git config alias.sdiff '!'"git diff && git submodule foreach 'git diff'"
$ git config alias.spush 'push --recurse-submodules=on-demand'
$ git config alias.supdate 'submodule update --remote --merge'
De cette manière, vous pouvez simplement lancer git supdate lorsque
vous souhaitez mettre à jour vos sous-module ou git spush pour pousser
avec une gestion de dépendance de sous-modules.
Les problèmes avec les sous-modules
Cependant, utiliser des sous-modules ne se déroule pas sans accroc.
Commuter des branches qui contiennent des sous-modules peut également s’avérer difficile. Si vous créez une nouvelle branche, y ajoutez un sous-module, et revenez ensuite à une branche dépourvue de ce sous-module, vous aurez toujours le répertoire de ce sous-module comme un répertoire non suivi :
$ git checkout -b add-crypto
Basculement sur la nouvelle branche 'add-crypto'
$ git submodule add https://github.com/chaconinc/CryptoLibrary
Clonage dans 'CryptoLibrary'...
...
$ git commit -am 'adding crypto library'
[add-crypto 4445836] adding crypto library
2 files changed, 4 insertions(+)
create mode 160000 CryptoLibrary
$ git checkout master
warning: unable to rmdir CryptoLibrary: Directory not empty
Basculement sur la branche 'master'
Votre branche est à jour avec 'origin/master'.
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Fichiers non suivis :
(utilisez "git add <fichier>..." pour inclure dans ce qui sera validé)
CryptoLibrary/
aucune modification ajoutée à la validation mais des fichiers non suivis sont présents (utilisez "git add" pour les suivre)
Supprimer le répertoire n’est pas difficile, mais sa présence est assez
déroutante. Si vous le supprimez puis que vous rebasculez sur la branche
qui contient le sous-module, vous devrez lancer
submodule update --init pour le repopuler.
$ git clean -ffdx
Suppression de CryptoLibrary/
$ git checkout add-crypto
Basculement sur la branche 'add-crypto'
$ ls CryptoLibrary/
$ git submodule update --init
Submodule path 'CryptoLibrary': checked out 'b8dda6aa182ea4464f3f3264b11e0268545172af'
$ ls CryptoLibrary/
Makefile includes scripts src
Une fois de plus, ce n’est réellement difficile, mais cela peut être déroutant.
Une autre difficulté commune consiste à basculer de sous-répertoires en
sous-modules. Si vous suiviez des fichiers dans votre projet et que vous
voulez les déplacer dans un sous-module, vous devez être très prudent ou
Git sera inflexible. Présumons que vous avez les fichiers dans un
sous-répertoire de votre projet, et que vous voulez les transformer en
un sous-module. Si vous supprimez le sous-répertoire et que vous
exécutez submodule add, Git vous hurle dessus avec :
$ rm -Rf CryptoLibrary/
$ git submodule add https://github.com/chaconinc/CryptoLibrary
'CryptoLibrary' already exists in the index
Vous devez d’abord supprimer le répertoire CryptoLibrary de l’index.
Vous pourrez ensuite ajouter le sous-module :
$ git rm -r CryptoLibrary
$ git submodule add https://github.com/chaconinc/CryptoLibrary
Cloning into 'CryptoLibrary'...
remote: Counting objects: 11, done.
remote: Compressing objects: 100% (10/10), done.
remote: Total 11 (delta 0), reused 11 (delta 0)
Unpacking objects: 100% (11/11), done.
Checking connectivity... done.
Maintenant, supposons que vous avez fait cela dans une branche. Si vous essayez de basculer dans une ancienne branche où ces fichiers sont toujours dans l’arbre de projet plutôt que comme sous-module, vous aurez cette erreur :
$ git checkout master
error: The following untracked working tree files would be overwritten by checkout:
CryptoLibrary/Makefile
CryptoLibrary/includes/crypto.h
...
Please move or remove them before you can switch branches.
Aborting
Vous pouvez le forcer à basculer avec checkout -f, mais soyez attentif
à ce qu’il soit propre ou les modifications seraient écrasées.
$ git checkout -f master
warning: unable to rmdir CryptoLibrary: Directory not empty
Basculement sur la branche 'master'
Ensuite, lorsque vous rebasculez, vous aurez un répertoire
CryptoLibrary vide et git submodule update pourrait ne pas le
remettre en état. Vous allez devoir vous rendre dans le répertoire de
votre sous-module et lancer git checkout . pour retrouver tous vos
fichiers. Vous pouvez lancer ceci dans un script submodule foreach
dans le cas de multiples sous-modules.
Il est important de noter que depuis les versions de Git récentes, les
sous-modules conservent leurs données Git dans le répertoire .git du
projet principal, ce qui à la différence des versions antérieures,
permet de supprimer le dossier du sous-module sans perdre les commits
et les branches qu’il contenait.
Avec ces outils, les sous-modules peuvent être une méthode assez simple et efficace pour développer simultanément sur des projets connexes mais séparés.
Empaquetage (bundling)
Bien que nous ayons déjà abordé les méthodes les plus communes de transfert de données Git par réseau (HTTP, SSH, etc.), il existe en fait une méthode supplémentaire qui n’est pas beaucoup utilisée mais qui peut s’avérer utile.
Git est capable d’empaqueter ses données dans un fichier unique. Ceci
peut servir dans de nombreux scénarios. Le réseau peut être en panne et
vous souhaitez envoyer des modifications à vos collègues. Peut-être
êtes-vous en train de travailler à distance et vous ne pouvez pas vous
connecter au réseau local pour des raisons de sécurité. Peut-être que
votre carte réseau ou votre carte wifi vient de tomber en panne.
Peut-être encore n’avez-vous pas accès à un serveur partagé, et vous
souhaitez envoyer à quelqu’un des mises à jour sans devoir transférer 40
commits via format-patch.
Ce sont des situations où la commande git bundle est utile. La
commande bundle va empaqueter tout ce qui serait normalement poussé
sur le réseau avec une commande git push dans un fichier binaire qui
peut être envoyé à quelqu’un par courriel ou copié sur une clé USB, puis
de le dépaqueter dans un autre dépôt.
Voyons un exemple simple. Supposons que vous avez un dépôt avec deux commits :
$ git log
commit 9a466c572fe88b195efd356c3f2bbeccdb504102
Author: Scott Chacon <schacon@gmail.com>
Date: Wed Mar 10 07:34:10 2010 -0800
second commit
commit b1ec3248f39900d2a406049d762aa68e9641be25
Author: Scott Chacon <schacon@gmail.com>
Date: Wed Mar 10 07:34:01 2010 -0800
first commit
Si vous souhaitez envoyer ce dépôt à quelqu’un et que vous n’avez pas
accès en poussée à un dépôt, ou que simplement vous ne voulez pas en
créer un, vous pouvez l’empaqueter avec git bundle create.
$ git bundle create repo.bundle HEAD master
Décompte des objets: 6, fait.
Delta compression using up to 2 threads.
Compression des objets: 100% (2/2), fait.
Écriture des objets : 100% (6/6), 441 bytes, fait.
Total 6 (delta 0), reused 0 (delta 0)
À présent, vous avez un fichier repo.bundle qui contient toutes les
données nécessaires pour recréer la branche master du dépôt. Avec la
commande bundle, vous devez lister toutes les références ou les
intervalles spécifiques de commits que vous voulez inclure. Si vous le
destinez à être cloné ailleurs, vous devriez aussi ajouter HEAD comme
référence, comme nous l’avons fait.
Vous pouvez envoyer ce fichier repo.bundle par courriel, ou le copier
sur une clé USB et la tendre à un collègue.
De l’autre côté, supposons qu’on vous a envoyé ce fichier repo.bundle
et que vous voulez travailler sur le projet. Vous pouvez cloner le
fichier binaire dans un répertoire, de la même manière que vous le
feriez pour une URL.
$ git clone repo.bundle repo
Initialized empty Git repository in /private/tmp/bundle/repo/.git/
$ cd repo
$ git log --oneline
9a466c5 second commit
b1ec324 first commit
Si vous n’incluez pas HEAD dans les références, vous devez aussi
spécifier -b master ou n’importe quelle branche incluse dans le paquet
car sinon, il ne saura pas quelle branche extraire.
Maintenant, supposons que vous faites 3 commits et que vous voulez renvoyer ces nouveaux commits via courriel ou clé USB.
$ git log --oneline
71b84da last commit - second repo
c99cf5b fourth commit - second repo
7011d3d third commit - second repo
9a466c5 second commit
b1ec324 first commit
Nous devons déjà déterminer l’intervalle de commits que nous voulons inclure dans le colis. À la différence des protocoles réseau qui calculent automatiquement l’ensemble minimum des données à transférer, nous allons devoir les définir manuellement. Ici, vous pourriez tout à fait lancer la même commande et empaqueter le dépôt complet, ce qui marcherait mais c’est mieux de n’empaqueter que la différence ‑ seulement les 3 commits que nous avons localement créés.
Pour le faire, vous allez devoir calculer la différence. Comme décrit
dans Plages de commits, vous pouvez faire
référence à un intervalle de commits de différentes manières. Pour
désigner les trois commits que nous avons dans notre branche master et
qui n’était pas dans la branche que nous avons initialement clonée, nous
pouvons utiliser quelque chose comme origin/master..master ou
master ^origin/master. Vous pouvez tester cela avec la sortie de la
commande log.
$ git log --oneline master ^origin/master
71b84da last commit - second repo
c99cf5b fourth commit - second repo
7011d3d third commit - second repo
Comme nous avons maintenant la liste des commits que nous voulons
inclure dans le colis, empaquetons-les. Cela est réalisé avec la
commande git bundle create, suivie d’un nom de fichier et des
intervalles des commits que nous souhaitons inclure.
$ git bundle create commits.bundle master ^9a466c5
Comptage des objets : 11, fait.
Delta compression using up to 2 threads.
Compression des objets : 100% (3/3), fait.
Écriture de objets : 100% (9/9), 775 bytes, fait.
Total 9 (delta 0), reused 0 (delta 0)
Nous avons à présent un fichier commits.bundle dans notre répertoire.
Si nous le prenons et l’envoyons à un partenaire, il pourra l’importer
dans le dépôt d’origine, même si du travail a été ajouté entre temps.
Quand il récupère le colis, il peut l’inspecter pour voir ce qu’il
contient avant de l’importer dans son dépôt. La première commande est
bundle verify qui va s’assurer que le fichier est une fichier bundle
Git valide et que le dépôt contient tous les ancêtres nécessaires pour
appliquer correctement le colis.
$ git bundle verify ../commits.bundle
Le colis contient 1 référence :
71b84daaf49abed142a373b6e5c59a22dc6560dc refs/heads/master
Le colis exige cette référence
9a466c572fe88b195efd356c3f2bbeccdb504102 second commit
../commits.bundle est correct
Si la personne avait créé un colis ne contenant que les deux derniers
commits qu’il avait ajoutés, plutôt que les trois, le dépôt initial
n’aurait pas pu l’importer, car il aurait manqué un commit dans
l’historique à reconstituer. La commande verify aurait ressemblé
plutôt à ceci :
$ git bundle verify ../commits-bad.bundle
error: Le dépôt ne dispose pas des commits prérequis suivants :
error: 7011d3d8fc200abe0ad561c011c3852a4b7bbe95 third commit - second repo
Cependant, notre premier colis est valide, et nous pouvons récupérer des commits depuis celui-ci. Si vous souhaitez voir les branches présentes dans le colis qui peuvent être importées, il y a aussi une commande pour donner la liste des sommets des branches :
$ git bundle list-heads ../commits.bundle
71b84daaf49abed142a373b6e5c59a22dc6560dc refs/heads/master
La sous-commande verify vous indiquera aussi les sommets. L’objectif
est de voir ce qui peut être tiré, pour que vous puissiez utiliser les
commandes fetch et pull pour importer des commits depuis le colis.
Ici, nous allons récupérer la branche master du colis dans une branche
appelée other-master dans notre dépôt :
$ git fetch ../commits.bundle master:other-master
Depuis ../commits.bundle
* [nouvelle branche] master -> other-master
Maintenant, nous pouvons voir que nous avons importé les commits sur
la branche other-master ainsi que tous les commits que nous avons
validés entre-temps dans notre propre branche master.
$ git log --oneline --decorate --graph --all
* 8255d41 (HEAD, master) third commit - first repo
| * 71b84da (other-master) last commit - second repo
| * c99cf5b fourth commit - second repo
| * 7011d3d third commit - second repo
|/
* 9a466c5 second commit
* b1ec324 first commit
Ainsi, git bundle peut vraiment être utile pour partager du code ou
réaliser des opérations nécessitant du réseau quand il n’y a pas de
réseau ou de dépôt partagé.
Replace
Git manipule des objets immuables mais il fournit un moyen de faire comme s’il pouvait remplacer des objets de sa base de données par d’autres objets.
La commande replace vous permet de spécifier un objet dans Git et de
lui indiquer : « chaque fois que tu vois ceci, fais comme si c’était
cette autre chose ». Ceci sert principalement à remplacer un commit
par un autre dans votre historique.
Par exemple, supposons que vous avez un énorme historique de code et que
vous souhaitez scinder votre dépôt en un historique court pour les
nouveaux développeurs et un plus important et long pour ceux intéressés
par des statistiques. Vous pouvez générer un historique depuis l’autre
avec replace en remplaçant le commit le plus ancien du nouvel
historique par le dernier commit de l’historique ancien. C’est sympa
parce que cela signifie que vous n’avez pas besoin de réécrire tous les
commits du nouvel historique, comme vous devriez le faire pour les
joindre tous les deux (à cause de l’effet de lien des SHA-1).
Voyons ce que ça donne. Prenons un dépôt existant, découpons-le en deux
dépôts, un récent et un historique, puis nous verrons comment les
recombiner sans modifier les valeurs SHA-1 du dépôt récent, grâce à
replace.
Nous allons utiliser un dépôt simple avec cinq commit simples :
$ git log --oneline
ef989d8 fifth commit
c6e1e95 fourth commit
9c68fdc third commit
945704c second commit
c1822cf first commit
Nous souhaitons couper ceci en deux lignes d’historiques. Une ligne ira de first commit à fourth commit et sera la ligne historique. La seconde ligne ira de fourth commit à fifth commit et sera ligne récente.

Bien, la création de la ligne historique est simple, nous n’avons qu’à
créer une branche dans l’historique et la pousser vers la branche
master d’un nouveau dépôt distant.
$ git branch history c6e1e95
$ git log --oneline --decorate
ef989d8 (HEAD, master) fifth commit
c6e1e95 (history) fourth commit
9c68fdc third commit
945704c second commit
c1822cf first commit

Maintenant, nous pouvons pousser la nouvelle branche history vers la
branche master du nouveau dépôt :
$ git remote add project-history https://github.com/schacon/project-history
$ git push project-history history:master
Décompte des objets : 12, fait.
Delta compression using up to 2 threads.
Compression des objets : 100% (4/4), fait.
Écriture des objets : 100% (12/12), 907 bytes, fait.
Total 12 (delta 0), reused 0 (delta 0)
Dépaquetage des objets : 100% (12/12), fait.
To git@github.com:schacon/project-history.git
* [nouvelle branche] history -> master
Bien, notre projet historique est publié. Maintenant, la partie la plus compliquée consiste à tronquer l’historique récent pour le raccourcir. Nous avons besoin d’un recouvrement pour pouvoir remplacer un commit dans un historique par un équivalent dans l’autre, donc nous allons tronquer l’historique à fourth commit et fifth commit, pour que fourth commit soit en recouvrement.
$ git log --oneline --decorate
ef989d8 (HEAD, master) fifth commit
c6e1e95 (history) fourth commit
9c68fdc third commit
945704c second commit
c1822cf first commit
Il peut être utile de créer un commit de base qui contient les instructions sur la manière d’étendre l’historique, de sorte que les autres développeurs puissent savoir comment s’y prendre s’ils butent sur le premier commit et ont besoin de plus d’histoire. Donc, ce que nous allons faire, c’est créer un objet commit initial comme base avec les instructions, puis rebaser les commits restants (quatre et cinq) dessus.
Nous avons besoin de choisir un point de découpe, qui pour nous est
third commit, soit le SHA-1 9c68fdc. Donc, notre commit de base
sera créé sur cet arbre. Nous pouvons créer notre commit de base en
utilisant la commande commit-tree, qui accepte juste un arbre et nous
fournit un SHA-1 d’un objet commit orphelin tout nouveau.
$ echo 'get history from blah blah blah' | git commit-tree 9c68fdc^{tree}
622e88e9cbfbacfb75b5279245b9fb38dfea10cf
La commande |
OK, donc maintenant avec un commit de base, nous pouvons rebaser le
reste de notre historique dessus avec la commande git rebase --onto.
L’argument --onto sera l’empreinte SHA-1 que nous venons tout juste de
récupérer avec la commande commit-tree et le point de rebasage sera
third commit (le parent du premier commit que nous souhaitons
garder, 9c68fdc).
$ git rebase --onto 622e88 9c68fdc
First, rewinding head to replay your work on top of it...
Applying: fourth commit
Applying: fifth commit
Bien, nous avons donc réécrit l’historique récent à la suite du commit de base qui contient les instructions pour reconstruire l’historique complet. Nous pouvons pousser ce nouvel historique vers un nouveau projet et quand des personnes clonent ce dépôt, elles ne voient que les deux commits les plus récents et un commit avec des instructions.
Inversons les rôles et plaçons-nous dans la position d’une personne qui clone le projet pour la première fois et souhaite obtenir l’historique complet. Pour obtenir les données d’historique après avoir cloné ce dépôt tronqué, on doit ajouter un second dépôt distant pointant vers le dépôt historique et tout récupérer :
$ git clone https://github.com/schacon/project
$ cd project
$ git log --oneline master
e146b5f fifth commit
81a708d fourth commit
622e88e get history from blah blah blah
$ git remote add project-history https://github.com/schacon/project-history
$ git fetch project-history
From https://github.com/schacon/project-history
* [nouvelle branche] master -> project-history/master
À présent, le collaborateur aurait les commits récents dans la branche
master et les commits historiques dans la branche
project-history/master.
$ git log --oneline master
e146b5f fifth commit
81a708d fourth commit
622e88e get history from blah blah blah
$ git log --oneline project-history/master
c6e1e95 fourth commit
9c68fdc third commit
945704c second commit
c1822cf first commit
Pour combiner ces deux branches, vous pouvez simplement lancer
git replace avec le commit que vous souhaitez remplacer suivi du
commit qui remplacera. Donc nous voulons remplacer fourth commit
dans la branche master par fourth commit de la branche
project-history/master :
$ git replace 81a708d c6e1e95
Maintenant, quand on regarde l’historique de la branche master, il
apparaît comme ceci :
$ git log --oneline master
e146b5f fifth commit
81a708d fourth commit
9c68fdc third commit
945704c second commit
c1822cf first commit
Sympa, non ? Sans devoir changer tous les SHA-1 en amont, nous avons pu
remplacer un commit dans notre historique avec un autre entièrement
différent et tous les outils normaux (bisect, blame, etc)
fonctionnent de manière transparente.
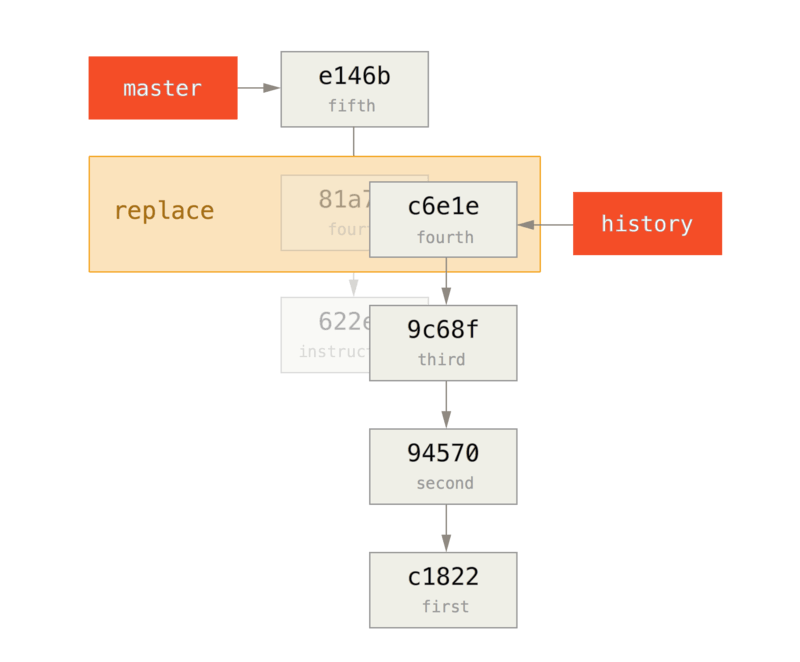
Ce qui est intéressant, c’est que fourth commit a toujours un SHA-1 de
81a708d, même s’il utilise en fait les données du commit c6e1e95
par lequel nous l’avons remplacé. Même si vous lancez une commande comme
cat-file, il montrera les données remplacées :
$ git cat-file -p 81a708d
tree 7bc544cf438903b65ca9104a1e30345eee6c083d
parent 9c68fdceee073230f19ebb8b5e7fc71b479c0252
author Scott Chacon <schacon@gmail.com> 1268712581 -0700
committer Scott Chacon <schacon@gmail.com> 1268712581 -0700
fourth commit
Souvenez-vous que le parent réel de 81a708d était notre commit de
base (622e88e) et non 9c68fdce comme indiqué ici.
Une autre chose intéressante est que les données sont conservées dans nos références :
$ git for-each-ref
e146b5f14e79d4935160c0e83fb9ebe526b8da0d commit refs/heads/master
c6e1e95051d41771a649f3145423f8809d1a74d4 commit refs/remotes/history/master
e146b5f14e79d4935160c0e83fb9ebe526b8da0d commit refs/remotes/origin/HEAD
e146b5f14e79d4935160c0e83fb9ebe526b8da0d commit refs/remotes/origin/master
c6e1e95051d41771a649f3145423f8809d1a74d4 commit refs/replace/81a708dd0e167a3f691541c7a6463343bc457040
Ceci signifie qu’il est facile de partager notre remplacement avec d’autres personnes, puisque nous pouvons pousser ceci sur notre serveur et d’autres personnes pourront le télécharger. Ce n’est pas très utile dans le cas de la reconstruction d’historique que nous venons de voir (puisque tout le monde téléchargerait quand même les deux historiques, pourquoi alors les séparer ?), mais cela peut être utile dans d’autres circonstances.
Stockage des identifiants
Si vous utilisez le transport SSH pour vous connecter à vos dépôts distants, il est possible d’avoir une clé sans mot de passe qui permet de transférer des données en sécurité sans devoir entrer un nom d’utilisateur et un mot de passe. Cependant, ce n’est pas possible avec les protocoles HTTP ‑ toute connexion nécessite un nom d’utilisateur et un mot de passe. Cela devient même plus difficile avec des systèmes à authentification à deux facteurs, où le mot de passe utilisé est généré dynamiquement au hasard et devient imprononçable.
Heureusement, Git dispose d’un système de gestion d’identifiants qui peut faciliter cette gestion. Git propose de base quelques options :
Par défaut, rien n’est mis en cache. Toutes les connexions vous demanderont votre nom d’utilisateur et votre mot de passe.
Le mode « cache » conserve en mémoire les identifiants pendant un certain temps. Aucun mot de passe n’est stocké sur le disque et les identifiants sont oubliés après 15 minutes.
Le mode « store » sauvegarde les identifiants dans un fichier texte simple sur le disque, et celui-ci n’expire jamais. Ceci signifie que tant que vous ne changerez pas votre mot de passe sur le serveur Git, vous n’aurez plus à entrer votre mot de passe. Le défaut de cette approche et que vos mots de passe sont stockés en clair dans un fichier texte dans votre répertoire personnel.
Si vous utilisez un Mac, Git propose un mode « osxkeychain », qui met en cache les identifiants dans un trousseau sécurisé attaché à votre compte système.
Si vous utilisez Windows, vous pouvez installer une application appelée « winstore ». C’est similaire à l’assistant « osxkeychain » décrit ci-dessus, mais utilise le Windows Credential Store pour sauvegarder les informations sensibles. winstore peut être téléchargé à https://gitcredentialstore.codeplex.com.
Vous pouvez choisir une de ces méthodes en paramétrant une valeur de configuration Git :
$ git config --global credential.helper cache
Certains de ces assistants ont des options. L’assistant « store »
accepte un argument --file <chemin> qui permet de personnaliser
l’endroit où le fichier texte est sauvegardé (par défaut, c’est
~/.git-credentials). L’assistant cache accepte une option
--timeout <secondes> qui modifie la période de maintien en mémoire
(par défaut, 900, soit 15 minutes). Voici un exemple de configuration de
l’option « store » avec un nom de fichier personnalisé :
$ git config --global credential.helper store --file ~/.my-credentials
Git vous permet même de configurer plusieurs assistants. Lors de la
recherche d’identifiants pour un serveur donné, Git les interrogera dans
l’ordre jusqu’à la première réponse. Pour la sauvegarde des
identifiants, Git enverra le nom d’utilisateur et le mot de passe à
tous les assistants et ceux-ci pourront choisir ce qu’ils en font.
Voici à quoi ressemblerait un .gitconfig si vous utilisiez un fichier
d’identifiants sur une clé USB mais souhaiteriez utiliser l’option de
cache pour éviter des frappes trop fréquentes si la clé n’est pas
insérée.
[credential]
helper = store --file /mnt/thumbdrive/.git-credentials
helper = cache --timeout 30000
Sous le capot
Comment tout ceci fonctionne-t-il ? La commande d’origine de Git pour le
système d’assistants d’indentification est git credential, qui accepte
une commande comme argument, puis d’autres informations via stdin.
Un exemple peut aider à mieux comprendre cela. Supposons qu’un assistant
d’identification a été configuré et que l’assistant a stocké les
identifiants pour mygithost. Voici une session qui utilise la commande
« fill » qui est invoquée quand Git essaie de trouver les identifiants
pour un hôte :
$ git credential fill (1)
protocol=https (2)
host=mygithost
(3)
protocol=https (4)
host=mygithost
username=bob
password=s3cre7
$ git credential fill (5)
protocol=https
host=unknownhost
Username for 'https://unknownhost': bob
Password for 'https://bob@unknownhost':
protocol=https
host=unknownhost
username=bob
password=s3cre7
| 1 | C’est la ligne de commande qui démarre l’interaction. |
| 2 | Git-credential attend la saisie d’informations sur stdin. Nous lui fournissons les informations que nous connaissons : le protocole et le nom d’hôte. |
| 3 | Une ligne vide indique que l’entrée est complète et le système d’identification devrait répondre avec les informations qu’il connaît. |
| 4 | Git-credential prend alors la main et écrit sur la sortie standard les informations qu’il a trouvées. |
| 5 | Si aucune information d’identification n’a été trouvée, Git demande le nom d’utilisateur et le mot de passe, et les fournit sur la sortie standard d’origine (ici elles sont rattachées à la même console). |
Le système d’aide à l’identification invoque en fait un programme
complètement séparé de Git lui-même. Lequel est invoqué et comment il
est invoqué dépendent de la valeur de configuration credential.helper.
Cette valeur peut prendre plusieurs formes :
| Valeur de configuration | Comportement |
|---|---|
|
lance |
|
lance |
|
lance |
|
Le code après |
Donc les assistants décrits ci-dessus sont en fait appelés
git-credential-cache, git-credential-store, et ainsi de suite et
nous pouvons les configurer pour accepter des arguments en ligne de
commande.
La forme générale pour ceci est git-credential-foo [args] <action>. Le
protocole stdin/stdout est le même que pour git-credential, mais en
utilisant un ensemble d’actions légèrement différent :
getest une requête pour une paire nom d’utilisateur/mot de passe.storeest une requête pour sauvegarder des identifiants dans la mémoire de l’assistant.erasepurge de la mémoire de l’assistant les identifiants répondants aux critères.
Pour les actions store et erase, aucune réponse n’est exigée (Git
les ignore de toute façon). Pour l’action get cependant, Git est très
intéressé par ce que l’assistant peut en dire. Si l’assistant n’a rien à
en dire d’utile, il peut simplement sortir sans rien produire, mais s’il
sait quelque chose, il devrait augmenter l’information fournie avec
celle qu’il a stockée. La sortie est traitée comme une série de
déclarations d’affectation ; tout ce qui est fourni remplacera ce que
Git connaît déjà.
Voici le même exemple que ci-dessus, mais en sautant git-credential et en s’attaquant directement à git-credential-store :
$ git credential-store --file ~/git.store store (1)
protocol=https
host=mygithost
username=bob
password=s3cre7
$ git credential-store --file ~/git.store get (2)
protocol=https
host=mygithost
username=bob (3)
password=s3cre7
| 1 | Ici nous indiquons à git-credential-store de sauvegarder des identifiants : le nom d’utilisateur (username) « bob » et le mot de passe (password) « s3cre7 » doivent être utilisés quand https://mygithost est accédé. |
| 2 | Maintenant, nous allons récupérer ces identifiants. Nous fournissons les parties de l’information de connexion que nous connaissons (https://mygithost), suivi d’une ligne vide. |
| 3 | git-credential-store répond avec le nom d’utilisateur et le mot de passe que nous avons précédemment stockés. |
Voici à quoi ressemble le fichier ~/git.store :
https://bob:s3cre7@mygithost
C’est juste une série de lignes, chacune contenant des URLs contenant
les informations d’identification. Les assistants osxkeychain et
winstore utilisent le format natif de leurs banques de stockage,
tandis que cache utilise son propre format en mémoire (qu’aucun autre
processus ne peut lire).
Un cache d’identifiants personnalisé
Étant donné que git-credential-store et consort sont des programmes
séparés de Git, il y a peu à penser que n’importe quel programme peut
être un assistant d’identification Git. Les assistants fournis par Git
gèrent de nombreux cas d’utilisation habituels, mais pas tous. Par
exemple, supposons que votre équipe dispose de certains identifiants qui
sont partagés par tous, pour le déploiement. Ils sont stockés dans un
répertoire partagé, mais vous ne les copiez pas dans votre propre
magasin d’identifiants parce qu’ils changent souvent. Aucun assistant
existant ne gère ce cas ; voyons ce qu’il faudrait pour écrire le nôtre.
Ce programme doit présenter certaines fonctionnalités clé :
La seule action à laquelle nous devons répondre est
get;storeeterasesont des opérations d’écriture, donc nous sortirons directement et proprement dans ces cas.Le format du fichier d’identifiants partagés est identique à celui utilisé par
git-credential-store.L’emplacement de ce fichier est assez standard, mais nous devrions pouvoir laisser l’utilisateur spécifier une chemin en cas de besoin.
Une fois de plus, nous écrirons cette extension en Ruby, mais n’importe quel langage fonctionnera, tant que Git peut lancer un exécutable à la fin. Voici le code source complet de ce nouvel assistant d’identification :
#!/usr/bin/env ruby
require 'optparse'
path = File.expand_path '~/.git-credentials' (1)
OptionParser.new do |opts|
opts.banner = 'USAGE: git-credential-read-only [options] <action>'
opts.on('-f', '--file PATH', 'Specify path for backing store') do |argpath|
path = File.expand_path argpath
end
end.parse!
exit(0) unless ARGV[0].downcase == 'get' (2)
exit(0) unless File.exists? path
known = {} (3)
while line = STDIN.gets
break if line.strip == ''
k,v = line.strip.split '=', 2
known[k] = v
end
File.readlines(path).each do |fileline| (4)
prot,user,pass,host = fileline.scan(/^(.*?):\/\/(.*?):(.*?)@(.*)$/).first
if prot == known['protocol'] and host == known['host'] then
puts "protocol=#{prot}"
puts "host=#{host}"
puts "username=#{user}"
puts "password=#{pass}"
exit(0)
end
end
| 1 | Ici, nous analysons les options de la ligne de commande, pour permettre à l’utilisateur de spécifier un fichier. Par défaut, c’est ~/.git-credentials. |
| 2 | Ce programme ne répondra que si l’action est get et si le fichier magasin existe. |
| 3 | Cette boucle lit depuis stdin jusqu’à la première ligne vide. Les entrées sont stockées dans le hash known pour référence ultérieure. |
| 4 | Cette boucle lit le contenu du fichier magasin, et recherche les correspondances. Si le protocole et l’hôte depuis known correspondent à la ligne, le programme imprime les résultats sur stdout et sort. |
Nous allons sauvegarder notre assistant comme
git-credential-read-only, le placer quelque part dans notre PATH et
le marquer exécutable. Voici à quoi ressemble une session interactive :
$ git credential-read-only --file=/mnt/shared/creds get
protocol=https
host=mygithost
protocol=https
host=mygithost
username=bob
password=s3cre7
Puisque son nom commence par git-, nous pouvons utiliser une syntaxe
simple pour la valeur de configuration :
$ git config --global credential.helper read-only --file /mnt/shared/creds
Comme vous pouvez le voir, étendre ce système est plutôt direct et peut résoudre des problèmes communs pour vous et votre équipe.
Résumé
Vous venez de voir certains des outils avancés vous permettant de manipuler vos commits et votre index plus précisément. Lorsque vous remarquez des bogues, vous devriez être capable de trouver facilement quelle validation les a introduits, quand et par qui. Si vous voulez utiliser des sous-projets dans votre projet, vous avez appris plusieurs façons de les gérer. À partir de maintenant, vous devez être capable de faire la plupart de ce dont vous avez besoin avec Git en ligne de commande et de vous y sentir à l’aise.